TL;DR – here’s a video that explains briefly what cockpit is, and then goes though how it can be installed, and more importantly how 2FA can be enabled to make access more secure than the out-of-the-box default of username/password. I also go over where to find other plugin applications that can help make Cockpit even more useful. Enjoy!
[Update – video now in MP4 format – thanks to @[email protected] for pointing this out]
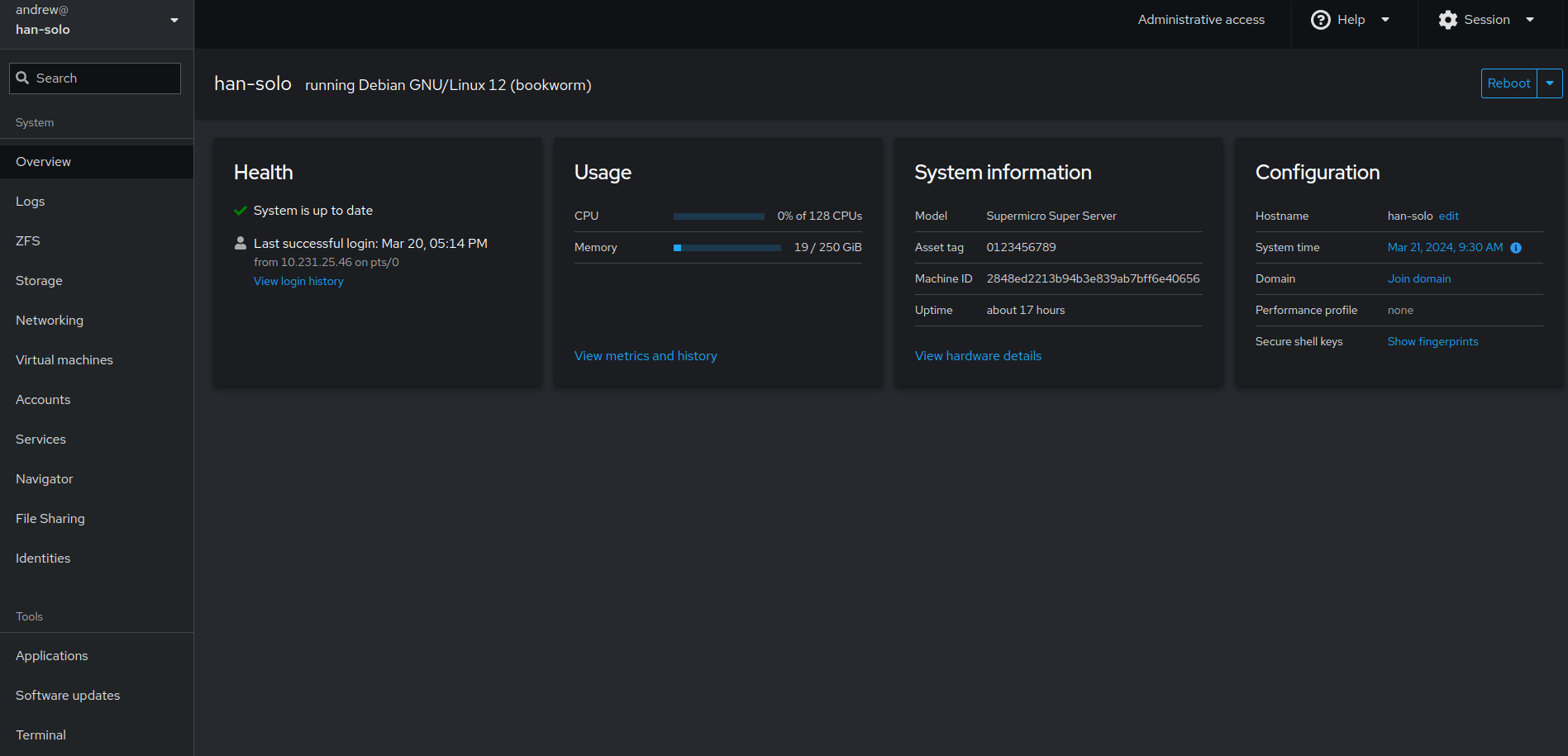
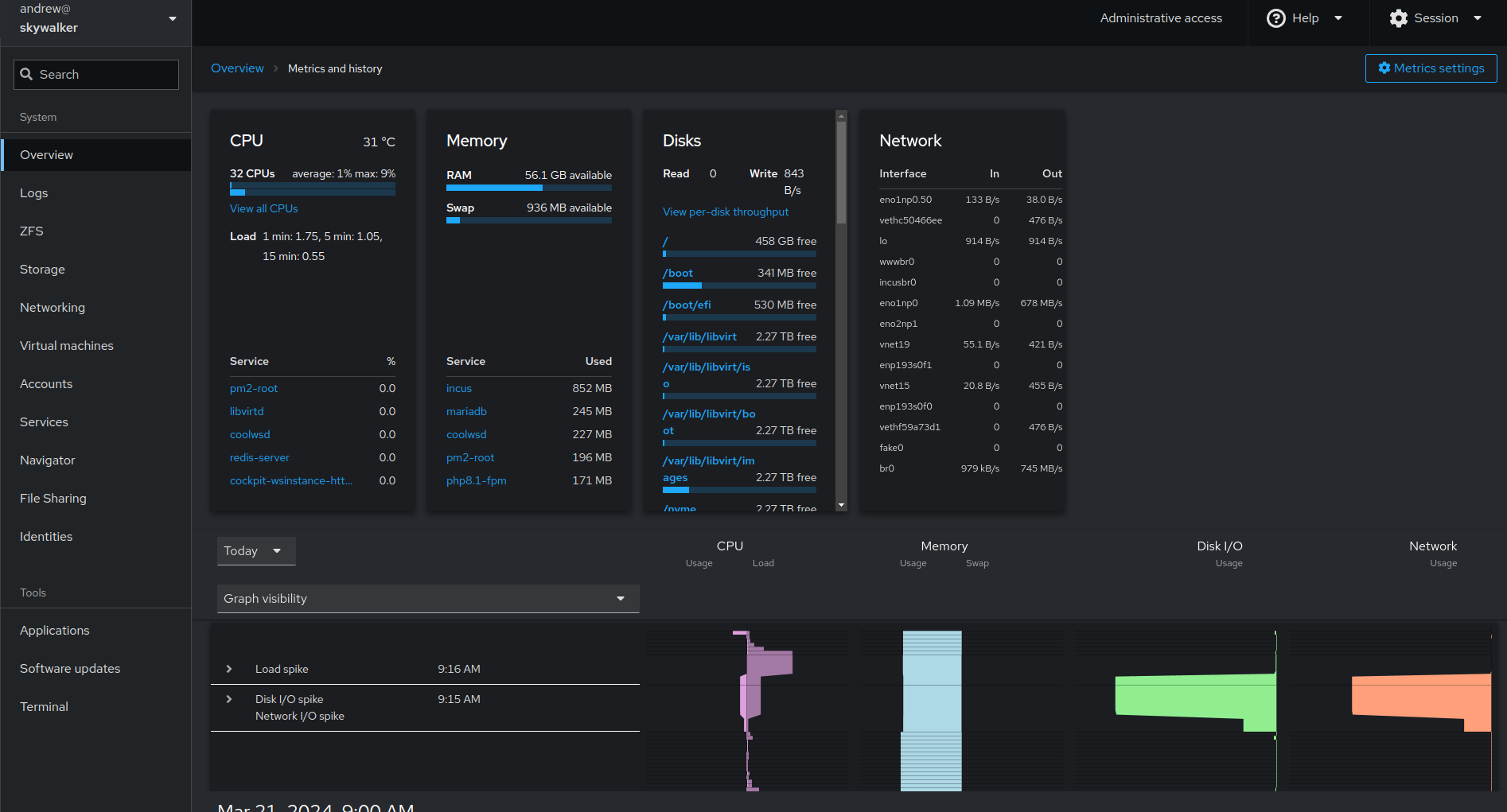
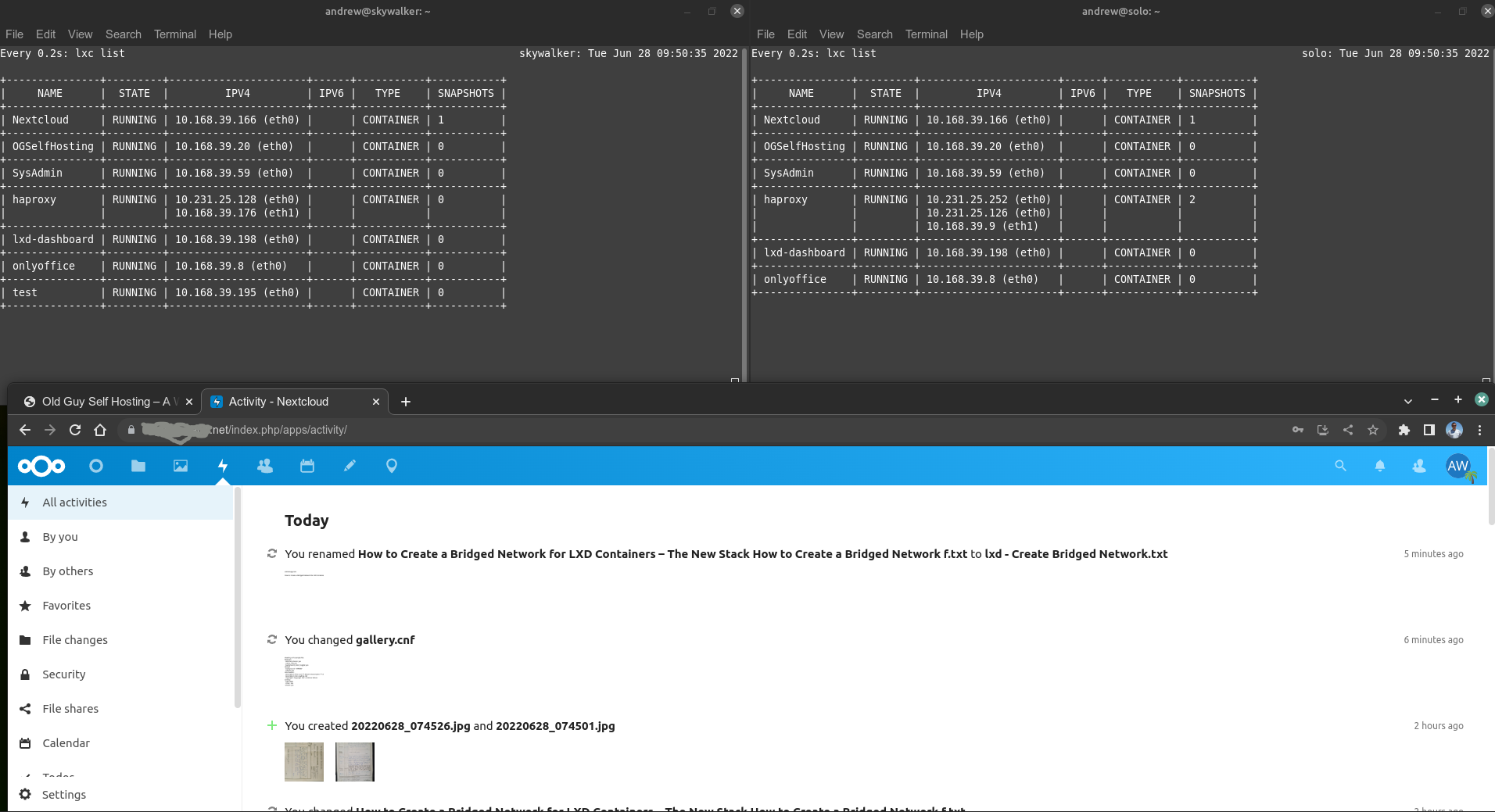
Cockpit is an open source project sponsored by Red Hat to provide a simple GUI management portal that aids linux server management. Installation is a breeze (‘sudo apt install cockpit && sudo systemctl enable –now cockpit). This gets you a portal that can be accessed simply by navigating your browser to https://server-ip:9090. You login with your linux credentials and basically you get an interface you can use for managing and inspecting some basic services. Here’s the overview screen for one of my actual linux servers:
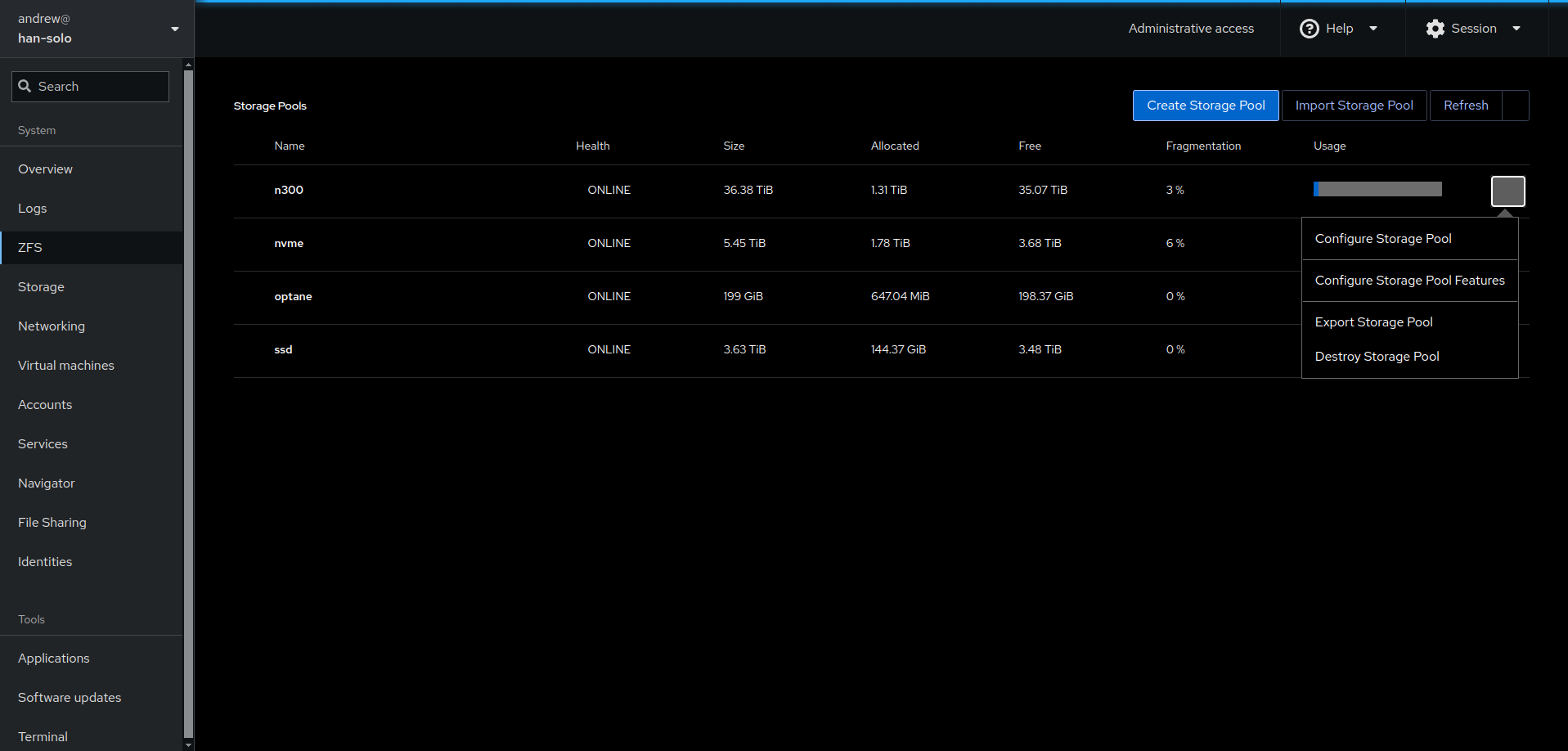
Cockpit comes pre-installed with several plugin ‘apps’ that expand and shape the functionality of the portal. You can add more plugins to make it even more useful (see my video) – e.g. for zfs service management:
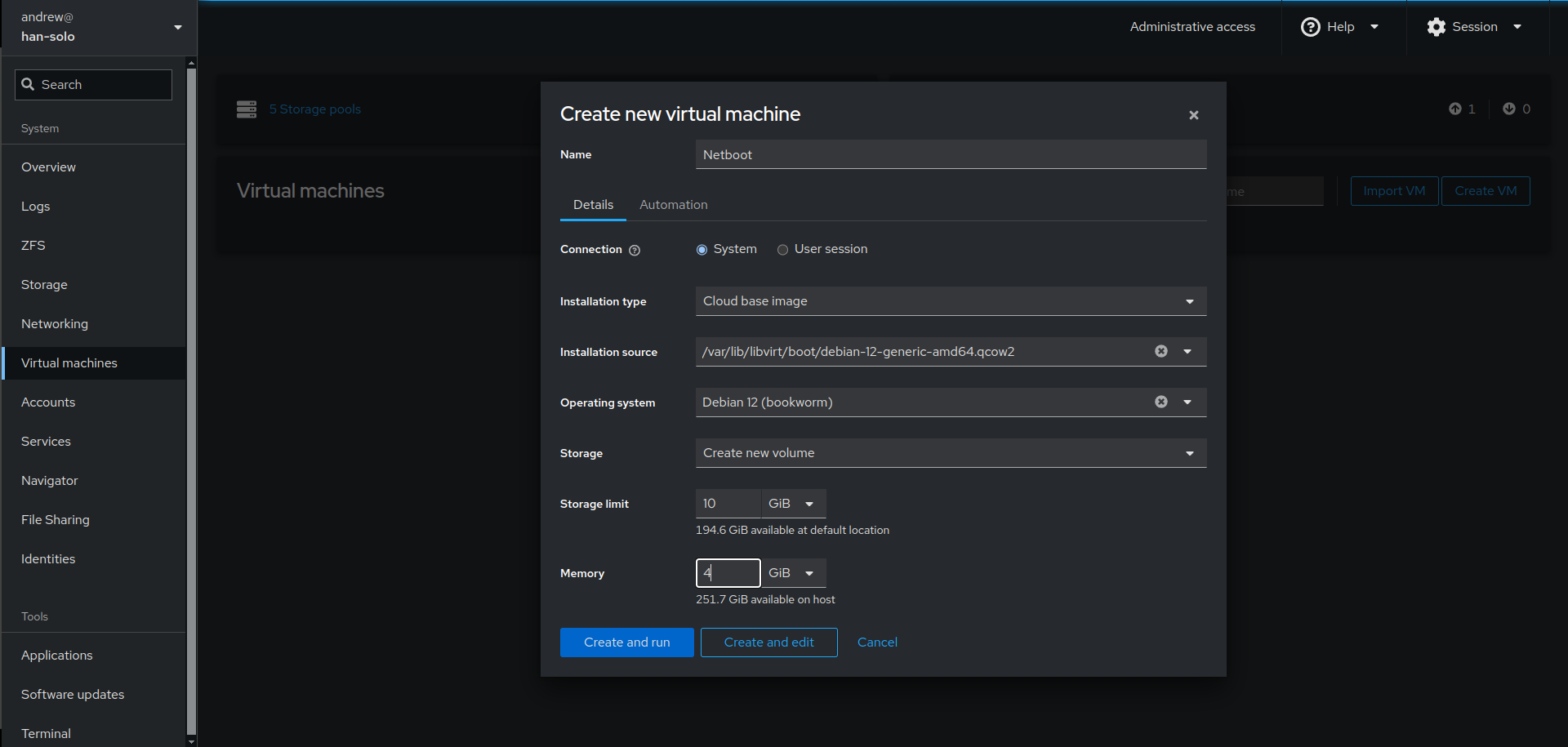
You can even create virtual machines in cockpit that can be further viewed and configured with virt-manager. I showcase this in my video as I use cockpit on my real server to…create a virtual machine…in which I install and create a cockpit service and enable 2FA in the virtualized cockpit instance (!)
Whilst this is not as feature-rich as e.g. proxmox or xcp-ng, cockpit provides for a very capable and easy-to-use hypervisor in terms of the machines it creates.
There are lots of videos and tutorials about cockpit that can inform on its capabilities.
One concern I have about the basic installation for cockpit is that it gives you essentially the same access to a server as an ssh-connection without a public-private key: all it takes to login to a cockpit server is a username and a password. That’s too weak from a security perspective for server access IMHO. To fix that, we can add two-factor authentication (2FA) to the login, requiring the use of a 6-digit code in addition to the (potentially weak) user credentials. Here’s how you do that e.g. for a Debian/Ubuntu server (or you can watch my view above):
Login to your server, install cockpit and google’s authenticator app run the following command (as user, not root):
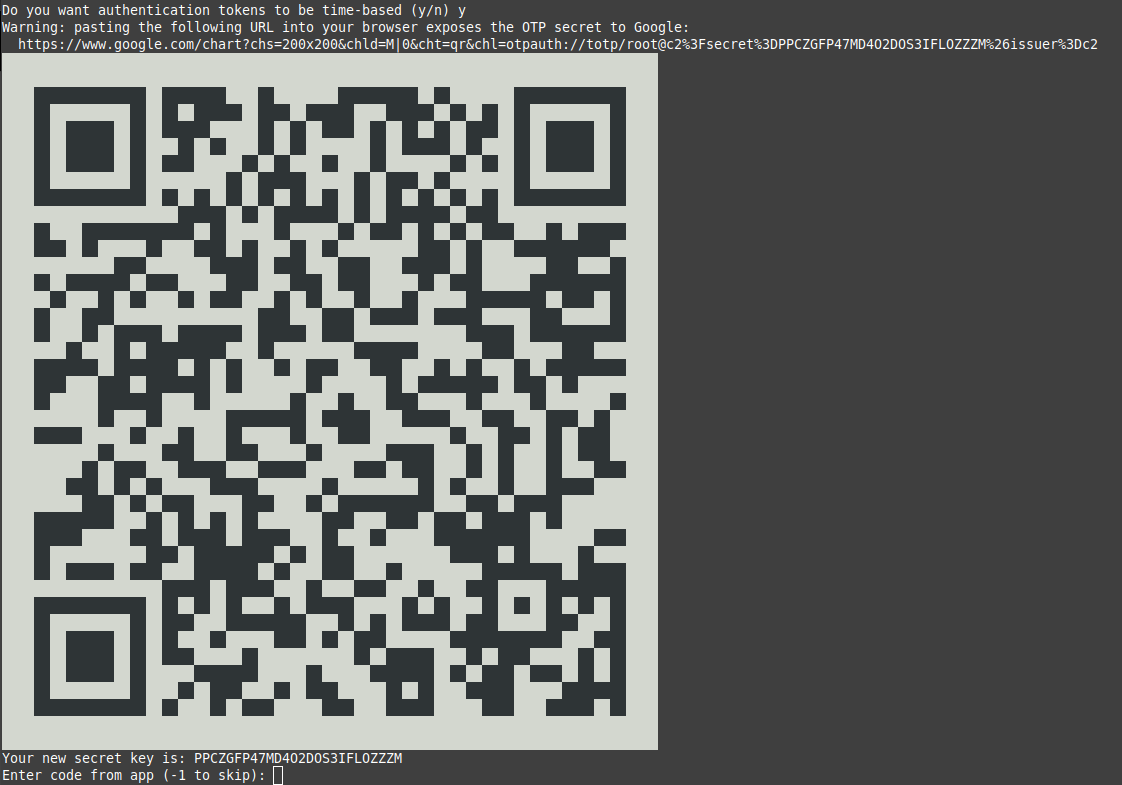
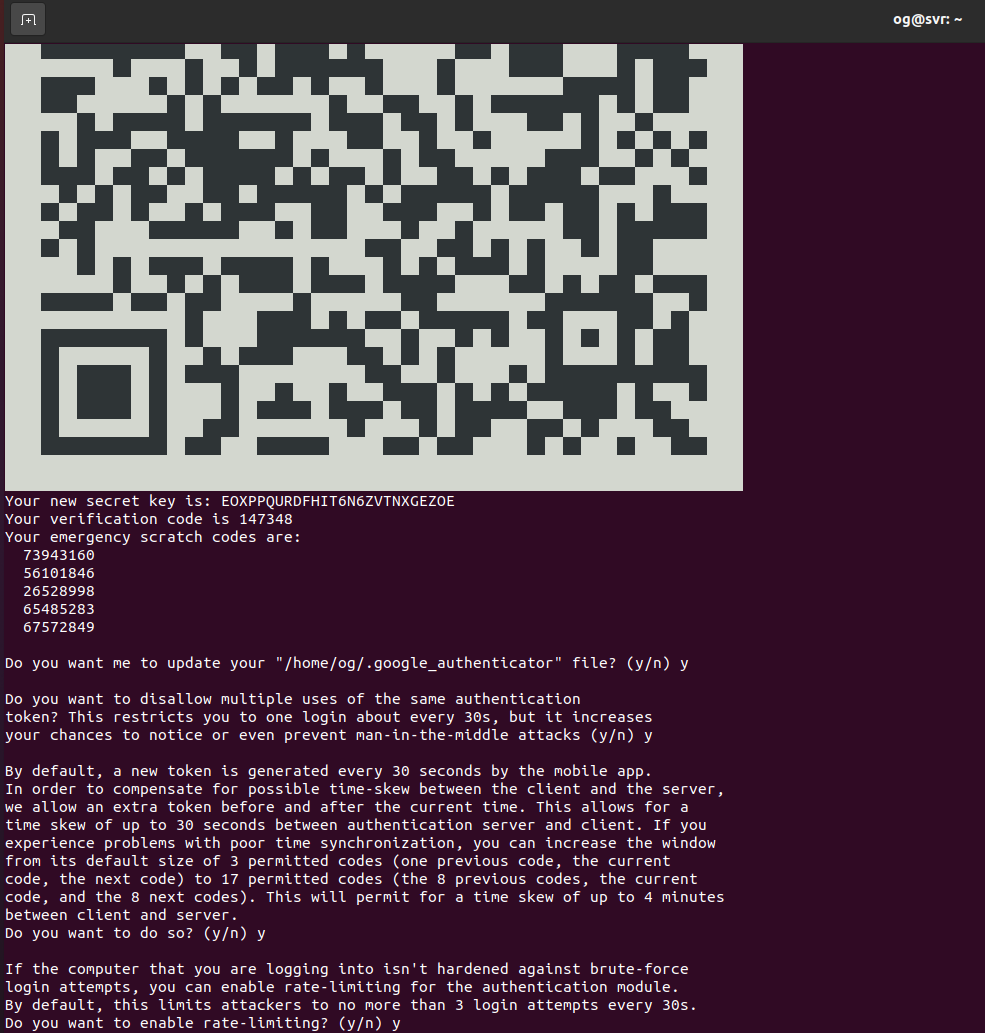
This updates your repositories, installs and enables cockpit, installs the authenticator app and runs it. After the installation, you will see an image similar to this as the 2FA app fires up:
Scan the QR code with your 2FA app, enter the code at the prompt and answer the questions to complete the process (answering ‘y’ is most secure, but even answering ‘n’ makes for a very secure 2FA setup – google-search if you want to know more). Now we need to tell cockpit to use 2FA: Edit the following file as root with your favorite editor, e.g nano:
sudo nano /etc/pam.d/cockpit
Add one line at the bottom of the file thus:
auth required pam_google_authenticator.so nullok
Save and quit, then issue the following:
sudo systemctl restart cockpit
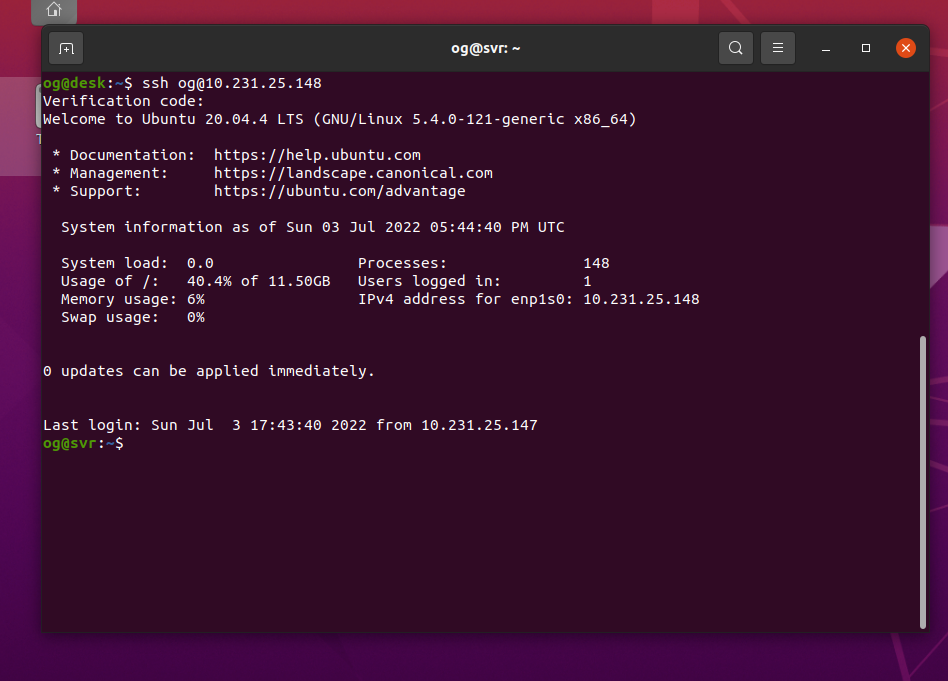
Then login to your cockpit server, enter your linux username, password:
When you attempt to login, you get a separate chhalenge for your 2FA 6-digit credential:
Use your phone app to get the current 2FA code (which changes every 30 seconds), enter it and you should be logged in, e.g.:
There you have it, 2FA cockpit enabled. This is now much more secure just as it should be for linux server access.
Bonus: for those who access their ssh servers over WAN (I don’t), you can add 2FA access to your ssh connections too. I have an article here that shows you how to do that “more conveniently” than the typical ssh-2FA implementations.
It’s a quiet Sunday, and I wasn’t planning on writing an article.
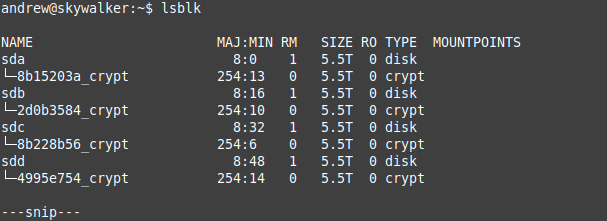
There I was copying files and doing some maintenance, and my network drive was offline. I figured I must have done something dumb, so I logged into my server and checked. My 8 x 6TB iron wolf raid-z2 zfs array was offline. So much for a quiet day.
Four of the eight disks were showing errors. And the ‘lsblk’ command could only find four of the eight disks:
Where have my drives gone?
In fact, I was a little relieved – one drive error might be real, but I thought 4 is probably a glitch. Hopefully software, but I have to troubleshot to find out. Here’s what I did. Firstly, server reboot – that should fix software issues, if any. It almost worked too: The drives reappeared, and the raid away came back to life. But then it died a few minutes later during a scrub I initiated. Again, FOUR disks gave errors. It’s probably not the software.
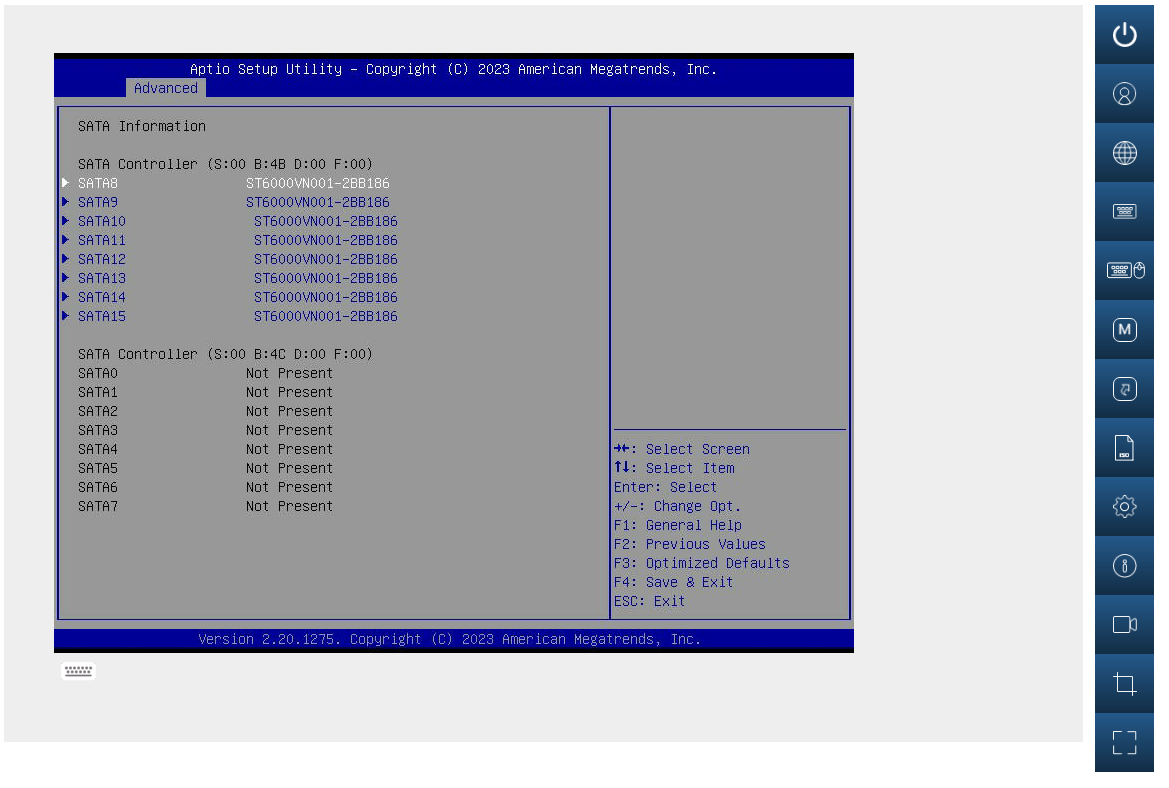
So I rebooted the server, logged into the IPMI interface and spammed the delete key a few times so I could check interrupt the reboot and enter the bios setup screen of my H12SSi-NT motherboard. I wanted to see what the motherboard could detect. The H12 motherboard has a pair of slim-SAS connectors, and I was using all of one of them:
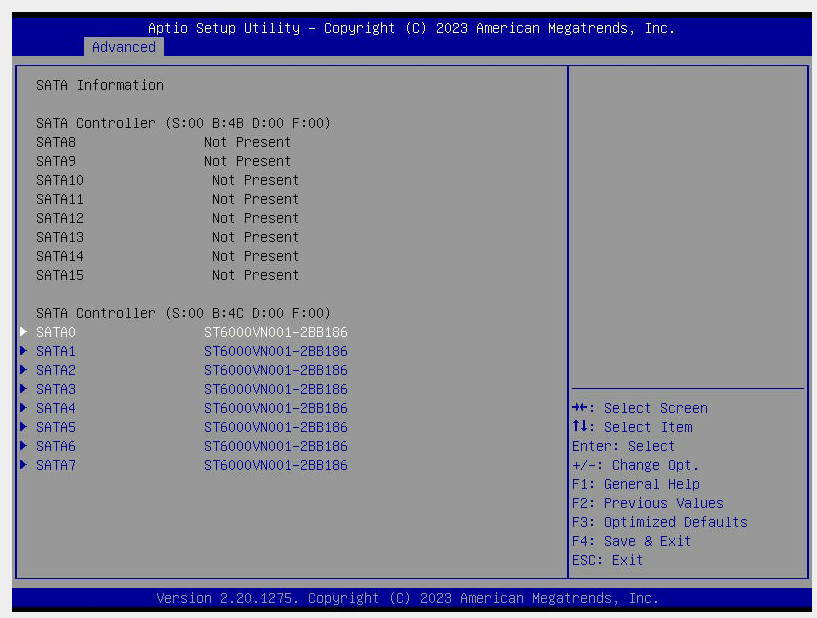
Both 8-port SATA connectors showed up, but I still wondered if the port I was using was somehow at fault (it’s a new motherboard… and wouldn’t make me smile if it was dead already). So I powered off, switched SAS port connectors and rebooted.
At power-up, however, the zpool array was still dead with four drives not showing.
Believe it or not, I felt BETTER: the chances of both SAS ports faulting is…low. And if the SATA ports were both working properly then it’s probably NOT the motherboard: remember that I said four drives were dead? Well each pair of four-drives is powered by a separate power cable connected to the single power supply. Could this be a dodgy power connection?
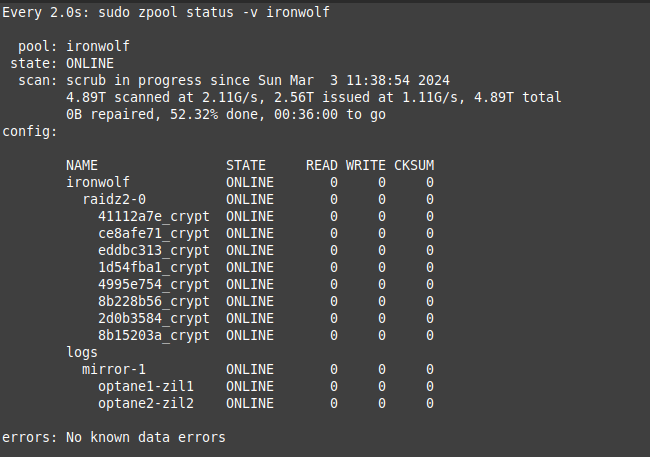
So I took the cover off and juggled the SATA power leads a little on each drive and on each power connector to the power supply. All the leads were all clicked-in-place, so I couldn’t easily see a problem. But I rebooted anyway as it’s an easy check. Wonder of wonders, on power-up, all eight drives reappeared and the zpool imported without issue.
As I type, I am scrubbing the zpool…but I am also going to order a new SATA power cable as I can’t really expect a ‘cable-jiggle’ to be a good long-term solution.
I also put my SAS connector back to the original port as the cabling was less stressful (I would have to re-route the cable to use that port permanently):
So the GOOD news is, I think it’s an inexpensive problem: a power lead. The BETTER news is that by systematically checking out the potential problems, I have a likely root-cause and a short-term fix (‘jiggling power leads’). I also have an executable plan for eliminating this (i.e. buy new (different?) power lead(s) for the drives).
TL;DR – Securely automate the decryption of your luks-encrypted Debian servers, to provide convenient yet substantial protection against data loss in the event of you losing some hardware. Here’s a video that goes through a real example of me encrypting a Debian 12 server using tang/clevis and showing the convenient yet substantially protective way it automatically decrypts my Debian servers on my home network:
The video clip includes me setting up two demo tang-servers in containers and using these servers to decrypt a luks-encrypted root file system on a Debian 12 server. All the instructions are in this blog post, but watching the video might make it easier for you to decide if this is for you. I encourage every Debian server user to luks-encrypt their drives to protect against data loss in the event of losing a disk (or even a whole server).
I ALWAYS luks-encrypt my linux drives, and I firmly believe you should too. Luks encryption is “full disk encryption”, and is typically used to protect against loss (including theft) of hardware. It ensures that your data are fully protected against physical hardware loss.
There are simply no exceptions to my rule of luks encrypting every drive I own. I do this because I don’t want my family’s data being accessed by anyone sleazy enough to e.g. break into my home and steal my hardware. It also makes it easy to dispose of a disk: disconnect if from power and put it in the trash. The contents are unreadable. No need to spend hours writing over each block of the disk to erase the contents. Quantum computing MAY make us revisit the impact of luks encryption, but today it’s still true: luks is solid.
Luks is a security measure and as such it can be “inconvenient” to use when it comes to boot disks and root file systems. To access luks-encypted drives you have to decrypt them, which typically means entering a password/key file to unlock them e.g. after power-up/reboot. For a desktop, that’s a completely acceptable task for me, but for bare-metal servers (and/or indeed virtual machine servers), this can be problematic.
There are TWO methods I use/have-used for decrypting luks servers: (1) dropbear-ssh (which allows you to gain ssh access to a luks-encrypted server during boot, so you can manually decrypt it) – this article is not about dropbear; (2) A combination of a tang-server and clevis package to automate that process to a large degree (the subject of this article).
There are many good articles on how to use dropbear-ssh and it’s pretty easy to do (google is your friend for researching this further). There are also tutorials on how to use clevis/tang. Most of these seem to be for Red Hat or maybe Ubuntu servers. I struggled a little to get clevis to work on my Debian 12 (Bookworm) servers, so I wanted to document how I do it. This is because I want to make it easy for YOU to luks-encrypt your Debian servers and thus strongly protect from equipment-theft based threats.
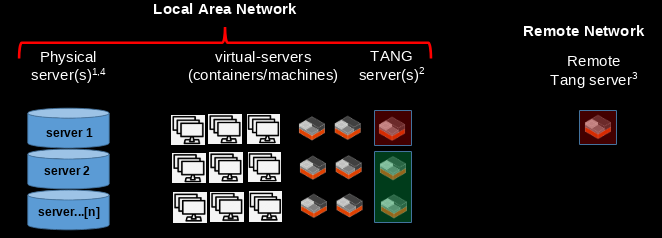
This article is however a little more targeted in that it also intended for someone who has MORE THAN ONE physical server. If you only have one, I am not sure it’s really worth having a tang/clevis system, since your services go offline during a re-boot no matter what. I personally have THREE physical servers in my home-lab (because I am a little very crazy), and I work hard to make sure at least one of them is always up. So I configure clevis/tang to restart any two servers that get power-cycled. If all of my servers get power-cycled at once, they cannot automatically decrypt via clevis. I designed it that way deliberately.
So how does tang/clevis (two different software packages), work together to decrypt a luks header “automatically”? Well there are many excellent articles on that subject (e.g. here, and here, so please check them out), but in summary form, here’s what you do to use it, and a simplified version of how it works:
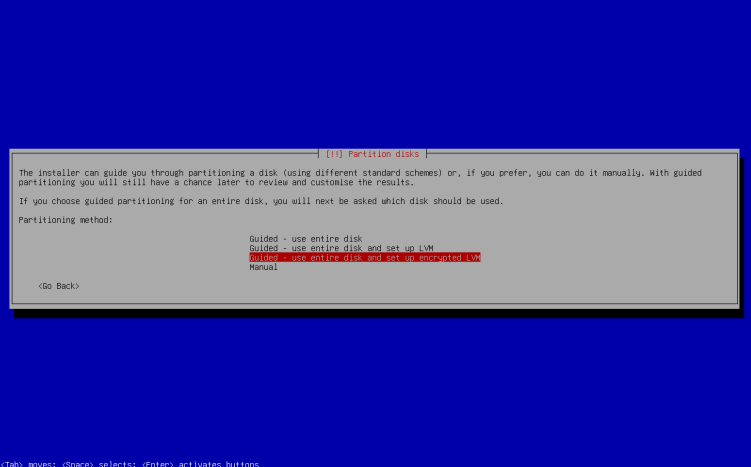
Install Debian server via an iso installer onto your hardware (or virtual machine) as usual, but during the disk partitioning screen, select the option for ‘Guided, use entire disk and setup encrypted lvm’ during the partitioning screen, e.g. for the net-install method for Debian12:
Enter a (very strong!!!) password at the ‘encryption passphrase’ prompt. This should use upper & lower case, symbols and numbers and should be awkwardly long to make brute-force impossible. For even better security, DO NOT USE A PASSWORD MANAGER, MAKE IT SOMETHING YOU CAN REMEMBER. NEVER WRITE IT DOWN, (Warning: if you forget this, bad things will happen to your data in terms of your ability to ever read them again!!).
Complete the rest of the installation as normal, which ends with a reboot.
Your first test: enter the luks encryption password when prompted to decrypt the OS root file-system and allow it to boot-up.
Your server is now ready to have clevis installed and be configured to auto-decrypt your luks root file-system.
HOW DO I USE TANG/CLEVIS?
Before we start typing commands, here’s how I actually run my tang-clevis setup: I actually run TWO tang services, one of which is remote (not on my LAN, but still under my (remote) control), and the other does run on my LAN. In fact, the LAN-based tang-server is a high-availability cluster that can provide a single (identical) tang service to any machine on my LAN as long as at least one of the tang servers is online.
So my bare-metal servers have to get blinded decryption keys from two separate services for them to auto-decrypt at boot. One of which is provided by my highly-available tang server on the LAN, the other tang server is, well, somewhere else. This setup allows me to simultaneously reboot any TWO of my three LAN-based servers and they will automatically decrypt and reboot IF both tang services are available.
This is a deliberately fragile service: if anything is up with a tang service, chances are I have to manually decrypt my servers. In practice, I rarely do, so this just quietly runs and does its thing. I like that. Worse case, I can always vpn into my LAN, access a server via the IPMI interface and manually enter a luks code, but I am safe if e.g. anyone steals my hardware: any one of my physical servers that goes offline will NOT boot up if ANY of the following conditions are true:
All servers have been power-cycled simultaneously (e.g. switched off/power-cut…or stolen!)
Any server is disconnected from my local network prior to being rebooted (e.g. a thief back at their evil headquarters)
If my remote tang-server goes offline for any reason (more on this below, because sometimes I make it go offline deliberately)
And of course all the other reasons why services can fail…all of which are usually unintended of course!
I like all this, it allows me to sleep safe. I may lose my hardware, but I won’t ever lose our family data to a thief who steals my hardware (this method offers no protection against online hackers by the way – keep good offline backups!!).
For my remote tang-server, I am also experimenting with a systemd service that I have written, that does one extra thing: it tracks the status of my LAN servers to see if they are online. If they are, it keeps the remote tang-server hot and ready to serve blinded keys to them. If a LAN server goes offline, the systemd service sets a timer – enough time to allow for an automated reboot. If the server remains OFFLINE, for any reason, beyond my timer (e.g. in a scenario where someone has stolen my hardware, taken it somewhere and is attempting to power it up to see if they can somehow get my tang keys), the remote tang server is taken offline and the system it is on is rebooted (and thus deliberately locked via luks). No more remote tang-server until and unless I manually bring it back online. This extra complication essentially protects against even sophisticated thieves trying to steal a single server and use the online ones to somehow get to my data. If all goes well (and frankly it pretty much always does), my LAN servers automatically come back up after a reboot, but if any fragility kicks-in, I am there to do it manually. Very cool. As I said, I may lose my hardware to thieves, just not my data.
TECHNICAL DETAILS
We need to create a tang server (or better yet two or even more) to provide a tang service, and we need to install and configure clevis on each of the Debian servers we have luks-encrypted (in my case, that means all my bare metal servers). And then we need to link our tang services to a physical server’s boot luks header. Below, I will go through the simple steps needed to complete all of this.
Pre-requisite
I am assuming you have two or more Debian luks-encrypted servers that you want to configure clevis on. You need root access to these and details of IP address and basic networking (network gateway IP etc.).
I also assume you have a means of running a container on these servers, so we can install the tang services. These tang services have to be online, available and accessible to the luks-encrypted Debian server, so that at boot time the encrypted server can access these tang services on at least one of the other LAN tang servers in order to auto-decrypt the luks-encrypted root file system. In practice, this gives you a LOT of options (my own setup is a more complicated derivative of this), but I will try to keep it simple below.
Tang Server(s)
Tang is a service, like e.g. a web server. It just sits there listening at a port for a request to encrypt/decrypt a phrase. So it’s easy to setup. Just spin up your preferred method of virtualization (e.g. an incus or docker/lxd/lxc container, or a vm if you prefer). Ideally, this virtual instance should be installed on all of your encrypted servers so that it can provide a tang service on your LAN if any one of your servers is online. This is not essential, but I feel it’s a more secure way to implement tang/clevis.
Create and login to the soon-to-be tang server. You can use as many different servers as you like (I use two in this example) to create two or more tang servers. Per below, just enter and execute one command with root privileges:
sudo apt install tang jose
Hit enter, confirm the installation and let it complete. That’s all you need to do. Note down the IP address of the container and exit the container.
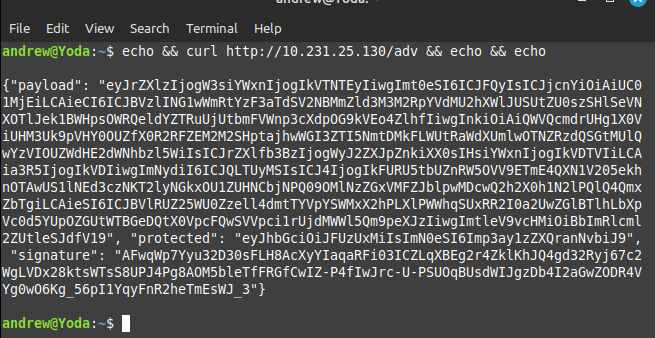
We can check that the tang service works by using a curl command. In the example below, I am assuming your IP address is 10.231.25.130. Change to suit:
curl http://10.231.25.130/adv
Just enter the above curl command (with the correct IP address) into a terminal and hit enter. Assuming you can connect to the server (i.e. on the same network) then the image below resembles what you should see (I use echo commands before and after, just to give some spacing in the output):
If you get a long string of similar looking “visual garbage” then…it’s working as it should! And that’s it. One tang server, ready to go. I recommend creating one on your LAN, and also one “somewhere else” (a distant friend/family’s computer, a hosting company that sells/rents vps’ etc. – somewhere pretty much out of the way). It’s not essential, it’s just how I do it. Once you set it up, just issue a ‘curl http:<ip-address>/adv’ command to fetch the advertising key per the above to see that it’s accessible as I show above. That’s it, one tang server ready to work for you (or indeed several of them).
[To make this even more secure, I recommend that you place at least one of these tang servers in a clustered high-availability mode on your network of encrypted physical servers. Doing so does mean that “at least one” of your LAN servers has to be online for this to work, which for most operations should be fine. If anyone wants to know more about this, just let me know (e.g. via @OGSelfHosting on X)]
Installing and Configuring Clevis
So now, let’s configure a luks encrypted server to coordinate with the tang services.
Login to your luks encrypted Debian server and enter a few commands as follows. Firstly, install clevis and it’s needed plugins:
For this next step we need networking information specific to your LAN. I am assuming you have TWO tang servers that you want to bind against a clevis key, setup as I showed earlier. I further assume these are accessible via the following ip addresses (change IP addresses to your tang servers):
When you use two servers, as I have done here, the clevis command uses a ‘shamir secret sharing’ (the ‘sss’ option), which basically instructs clevis to use two (or more) tang-servers to create a fragmented blinded luks key. If one of these tang-servers is on your LAN (especially on one of your encrypted servers), and one is in a distant location, this makes the service very very secure. Probably as good as it can be given that this is “automated”.
When you enter the above command, clevis asks for your luks decryption password (enter it accordingly), then it checks the tang servers and asks if you want to trust them (review and confirm). Clevis does some checks on the data and if there are no errors, it creates a new luks header key using a key derived from numbers sent back from the two tang-servers via a clevis-initiated prompt. Note that neither tang-server knows the luks password, they merely return a fragmented blinded code which on its own cannot decrypt a luks disk. Only clevis (and luks) know this password. Your old luks password WILL STILL WORK AS NORMAL but now there’s a new key that clevis can use to unlock the root partition at boot. But we are not done yet, we have to do some configuration so that there is network access during boot-up. Edit the following file on your Debian server:
sudo nano /etc/initramfs-tools/initramfs.conf
The initramfs file allows you to specify information about your network. if you google initramfs you can find a lot more information, e.g. here. We are going to specify some of our networking – just enough to get an IP address on the LAN and internet access. Change these to suit your setup, then add this line at the end of the above file and save/quit. The items in bold will likely need changing. The network mask as shown below works for a /24 network (likely good enough for most people), but if you are running something more sophisticated then change this too.
The IP config has to be right for clevis to work (but you can always edit this file after a boot, so it’s not world-ending if you make a mistake). Do not miss out the single and double colons. Google-search initramfs if you want to know more, but basically this sets ups most of the networking needed for clevis to go find a tang server. Save and quit the config file change when done. We have one more file to create, to allow us to potentially connect to remote tang servers (if required):
sudo nano /usr/share/initramfs-tools/hooks/curl
Paste the following commands into the file (which I got from this link). It provides a name-server capability during boot then save/quit (so that tang can convert e.g. “remote-tang.mydomain.com” into an actual IP address), which you need if a tang-server is actually located on another network (i.e. remote):
#!/bin/sh -e
PREREQS=""
case $1 in
prereqs) echo "${PREREQS}"; exit 0;;
esac
. /usr/share/initramfs-tools/hook-functions
#copy curl binary
copy_exec /usr/bin/curl /bin
#fix DNS lib (needed for Debian 11)
cp -a /usr/lib/x86_64-linux-gnu/libnss_dns* $DESTDIR/usr/lib/x86_64-linux-gnu/
#fix DNS resolver (needed for Debian 11 + 12)
echo "nameserver 1.1.1.1\n" > ${DESTDIR}/etc/resolv.conf
#copy ca-certs for curl
mkdir -p $DESTDIR/usr/share
cp -ar /usr/share/ca-certificates $DESTDIR/usr/share/
cp -ar /etc/ssl $DESTDIR/etc/
Now save the file/quit, make it executable then update the initramfs image. Then reboot as we are all DONE:
sudo chmod 755 /usr/share/initramfs-tools/hooks/curl
sudo update-initramfs -u -k 'all'
sudo reboot #This is optional, but it's how we test it. :)
If everything works as expected, you will watch your server boot up, ask for a luks key, enable networking (get an IP, connect to the adapter etc.) then it will try and contact the tang servers. Assuming success, watch the service magically unlock your encrypted server drive and for the system to boot up as if you entered the luks key yourself. It’s a satisfying thing to watch!
You can stop a tang server to disable auto-luks decryption, and that is an extra layer of protection you can further configure to make this convenient yet substantially protective.
if you have avoided luks encryption because of the inconvenience of having to connect to your server every time you reboot, PLEASE think again. Tang and clevis make this super convenient yet I believe also extremely secure.
If there’s any interest, I’ll update on my ‘systemd’ optimization on my remote server, which I think makes this “better than a human” at protecting my luks-encrypted Debian servers during reboot, making it extremely particular about how a server can actually reboot and auto-decrypt.
I hope you found this tutorial useful. Message me if you have any questions or comments, e.g. at @OGSelfHosting on X.
People who know me know I am a huge fan of virtualization using Cannonical’s lxd. I have been using lxd to create self-hosted web-facing lxc containers since 2016 (when lxd was running as version 2), with high (albeit imperfect) uptime. Over this period, I have added additional computing resources to my home network to improve uptime, user-experience, improved availability and overall performance (I’m a geek, and I like home network play as a hobby). One of the most important asset classes has been Nextcloud, my single most important self-hosted instance that helps me retain at least some of my digital privacy and to also comply with regulations that apply to digital information stored and used as part of my chosen career. I operate two instances of Nextcloud – one for work, one for personal. It’s been a journey learning how to configure them and keep them performing as optimally as I can get them.
I thought it might be good to document some of the methods I use to configure and maintain high availability of my self-hosted services, including Nextcloud. In the hopes that others might learn from this and maybe adopt/adapt to their own needs. I muddy the lines a bit between ‘backup’ and ‘high-availability’ because the technique I use for one, I also sort-of use for the other (that will become clearer below I hope). I backup not just my two Nextcloud instances using the method below, but also this web site and several other services I rely upon (about 11 critical containers as of today, growing slowly but steadily).
Using my high-availability/backup method actually makes it really hard for me to not be online with my services (barring electrical and ISP outages – like many, I don’t have much protection there). I don’t guarantee to never have problems, but I think I can say I am guaranteed to back online with like 99-100%+ of my services even if my live server goes down.
Firstly, for the majority of my self-hosted services, I run them mostly under lxd. Specifically as lxd containers. These are very fast and, well, completely self-contained. I tend to use the container for everything – including the storage requirements the container needs. My Nextcloud containers are just shy of 400GB in size today (large, unwieldy or so you would think), but most of them are just a few GB in size (such as this web site). If I can’t containerize a service, I use a virtual-machine (vm) instead of a container. Seldom though do I use lxd vm’s, I typically use virt-manager for that as I think it’s better suited. My Nextcloud instances run in lxd containers. When I first started using Nextcloud, I had one (small) Nextcloud container running on just one server. If it went down, as it did from time to time (almost always “operator error” driven), I had downtime. That started to become a problem, especially as I started sharing project files with customers so they needed links to just WORK.
So, even several years ago, I started looking at how to get good backups and high availability. The two seemed to be completely different, but now my solution to both is the same. Back then, there was no “copy –refresh” option (see later), so I was left trying to sync ever-growing containers to different machines as I built up my physical inventory. I repurposed old laptops to run as servers to give myself some redundancy. They worked. Well they half worked, but even then I still had blackouts that were not because of ISP or power-utility issues – they were my server(s) not working as I intended them to. My system has evolved substantially over the years, and I am now feeling brave enough to brag on it a little.
For my home network, I run three independent hot servers “all the time” (these are real machines, not VM’s). I have two proper servers running EPYC processors on Supermicro motherboards with way too much resources (#overkill), and I also have a server that’s based on consumer components – it’s really fast, not that the others are slow. Each server runs Ubuntu as the Operating System. Yes that’s right, I don’t use proxmox or other hypervisor to run my vm’s – everything is run via virtualizion on Ubuntu. Two of my live physical servers run Ubuntu 20.04, one runs 22.04 (I upgrade very slowly). In fact, I also run another local server that has a couple of Xeon processors, but I just use that for experiments (often wiping and re-installing various OS’s when a vm just won’t do for me). Finally, but importantly, I have an old System76 Laptop running an Intel i7 CPU and 20GB ram – I use this as a very (VERY) remote backup server – completely different network, power supply, zip code and host-country! I won’t go into any more details on that, but it’s an extension of what I do locally (and lxc copy –refresh is KEY there too – see later). LOL. Here’s some details of my current home servers for the curious:
Server Name
CPU
RAM
Obi-wan Kenobe
Dual EPYC 7H12’s
512 GB ECC x 3200MHz
Han Solo
Dual Epyc 7601’s
256GB ECC x 2600 MHz
Skywalker
Ryzen 3900X
128GB ECC x 3200 MHz
Darth Vader
Intel i7-7500U
20GB non-ECC x 2133MHz
Dooku
Dual Xeon 4560’s
24GB ECC x 1600 MHz
Note – you wouldn’t guess, but I am a bit of a Star Wars fan 🙂
The above servers are listed in order of importance to me. Obi-Wan Kenobe (or ‘obiwan’ per the actual /etc/hostname) is my high-end system. AMD EPYC 7H12’s are top of the line 64-core EPYC ROME CPU’s. I got mine used. And even then, they weren’t terribly cheap. Complete overkill for self-hosting but very cool to play with. Here’s my main ‘obiwan’ Epyc server:
Each of the servers Obiwan, Solo and Skywalker run lxd 5.0 under the Ubuntu OS (i.e the latest stable LTS version of lxd, not just the latest version), and each of them are using NVMe storage for the primary lxd default zpool for the containers:
zpool status lxdpool pool: lxdpool state: ONLINE scan: scrub repaired 0B in 00:16:54 with 0 errors on Sat Mar 11 19:40:55 2023 config:
NAME STATE READ WRITE CKSUM
lxdpool ONLINE 0 0 0
nvme2n1_crypt ONLINE 0 0 0
nvme3n1_crypt ONLINE 0 0 0
errors: No known data errors
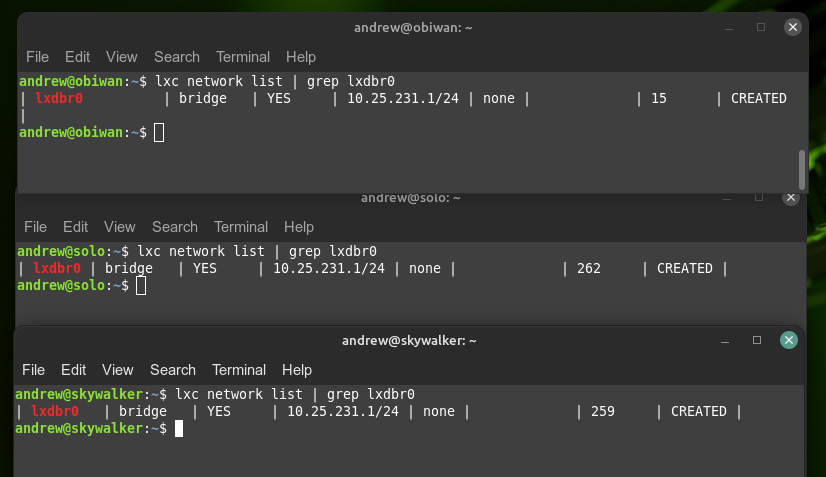
Each of these lxd zfs storage pools is based on 2TB NVMe drives or multiples thereof. The lxd instance itself is initialized as a separate, non-clustered instance on each of the servers, each using a zfs zpool called ‘lxdpool’ as my default backing storage and each configured with a network that has the same configuration in each server. I use 10.25.231.1/24 is the network for the lxdbr0. This means I run three networks with the same IP as subnets under my lab.:
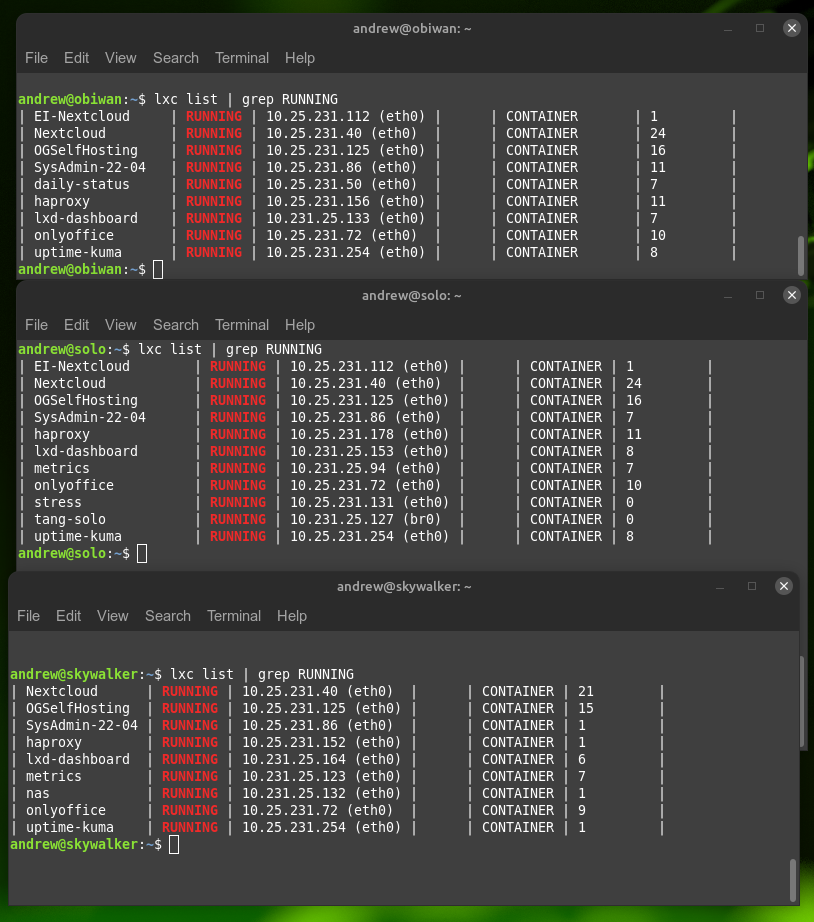
This is very deliberate on my part as it allows me to replicate containers from one instance to another – and to have each server run the same container with the same ip. Since these are self-contained subnets, there’s no clashing of addresses, but it makes it easy to track and manage how to connect to a container, no matter what server it is on. I host several services on each server, here’s some of them, as they are running on each server now:
So to be clear, most (not all) of the containers have the exact same IP address on each server. Those are the ones I run as part of my three-server fail-over high availability service.
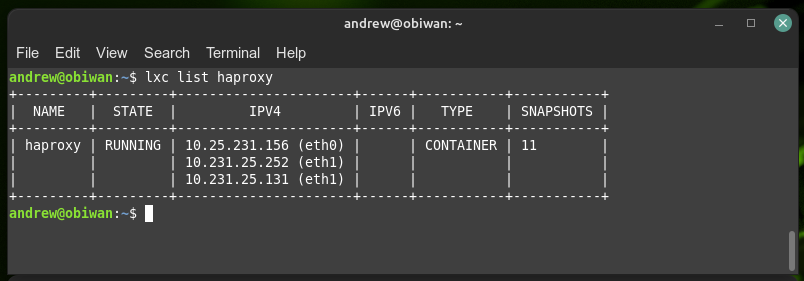
My haproxy container is the most unique one as each of them is in fact configured with three IP addresses (only one is shown above):
This is because my haproxy is my gateway for each lxd vm/container on each of the servers. If a web service is called for, it all goes via haproxy on the physical server. Note that two of the IP’s are from the same are from DHCP on my home LAN (10.231.25.1/24), whereas my servers each have their lxd networks configured using lxd DHCP from 10.25.231.1/24 (I chose to keep a similar numbering system for my networks as it’s just easier for me to remember). Importantly, my home router sends all port 80/443 traffic from www to whatever is sitting at IP 10.231.25.252. So that address is the HOT server, and it turns out, it’s very easy to switch that from one live server that goes down, immediately to a stand-by. This is keep to my high availability.
The 10.231.25.131 is unique to the Obiwan haproxy container, whereas 10.231.25.252 is unique to the HOT instance of haproxy via keepalived. On each of the other two hot servers, they are also running keepalived and they have a 10.231.25.x IP address. They ONLY inherit the second, key ip address of 10.231.25.252 if Obiwan: goes down – that’s the beauty of keepalived. It works transparently to me to keep a hot instance of 10.231.25.252 – and it changes blindingly fast if the current hot instance goes down (it’s a bit slower to change back ~5-10 seconds, but I only need one fast way so that’s cool).
So, if Obiwan goes down, one of my other two servers pick up the 10.231.25.252 IP *instantly* and they become the recipient of web traffic on ports 80 and 443. (Solo is second highest priority server after Obwan, and Skywalker is my third and final local failover). And since each server is running a very well synchronized copy of the containers running on Obiwan, there’s no disruption to services – virtually, and many times actually, 100% of the services are immediately available if a fail-over service is being deployed live. This is the basis for my lan high-availability self-hosted services. I can (and sometimes have to) reboot servers and/or they suffer outages. When that happens, my two stand-by servers kick in – Solo first, and if that goes down, Skywalker. As long as they have power. Three servers might be overkill for some, but I like redundancy more than I like outages – three works for me. Two doesn’t always work (I have sometimes had two servers dead a the same time – often self-inflicted!). Since I have been operating this way, I have only EVER lost services during a power cut or when my ISP actually goes down (I do not attempt to have redundancy from these). I’d say that’s not bad!
Here is a short video demonstrating how my high-availability works
So how do I backup my live containers and make sure the other servers can take over if needed?
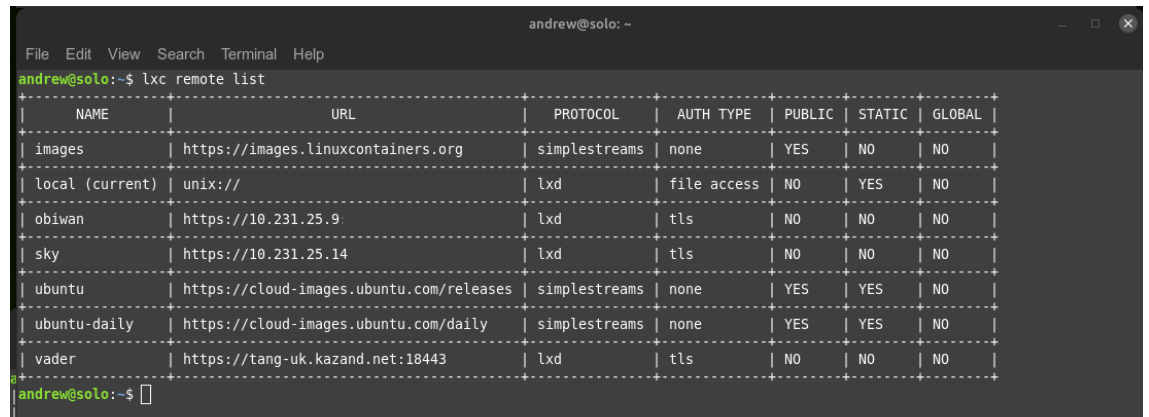
Firstly, even though I don’t use lxd clustering, I do connect each of the other two independent lxd servers to Obiwan, via the ‘lxd remote add’ feature. Very very cool:
2. Each lxd server is assigned the same network address for the default lxdbr0 (this is important, as using a different numbering system can sometimes mess with lxd when trying to ‘copy –refresh’).
3. Each server also has a default zfs storage zpool called ‘lxdpool’ (this is also important). And I use the same backging storage as sometimes I have foound even that to behave oddly with copy –refresh actions.
4. Every X minutes (X is usually set to 30, but that’s at my choosing via cron) I execute essentially the following script at each of Solo and separately at Skywalker servers (this is the short version, I actually get the script to do a few more things that are not important here):
cnames="nextcloud webserver-name etc." For i = name in $cnames do /snap/bin/lxc stop $name /snap/bin/lxc copy obiwan:$name $name --refresh /snap/bin/lxc start $name done
Remarkably, what this simple ‘lxc copy –refresh’ does is to copy the actual live instance of my obiwan server containers to solo and skywalker. Firstly it stops the running container on the backup server (not the live, hot version), then it updates the backup version, then it restarts it. The ‘updating it’ is a key part of the process and lxc ‘copy –refresh’ makes it awesome. You see, when you copy a lxd instance from one machine to another, it can be a bit quirky. A straight ‘lxc copy’ (without the –refresh option) action changes IP and mac address on the new copy, and these can make it difficult to keep track of in the new host system – not good for fail-over. When you use –refresh as an option, it does several important things. FIRSTLY, it only copies over changes that have been made since the last ‘copy –refresh’ – so a 300GB container doesn’t get copied from scratch every time – maybe a few MB or few GB – not much at any time (the first copy takes the longest of course). This is a HUGE benefit, especially when copying over WAN (which I do, but won’t detail here). It’s very fast! Secondly, the IP address and even the MAC address are unchanged in the copy over the original. It is, in every way possible, IDENTICAL copy to the original. That is, to say the least, very handy, when you are trying to create a fail-over service! I totally love ‘copy –refresh’ on lxd.
So a quick copy –refresh every 30 minutes and I have truly hot stand-by servers sitting, waiting for “keepalived” to change their IP so they go live on network vs being in the shadow as a hot backup. Frankly I think this is wonderful. I could go for more frequent copies but for me, 30 minutes is reasonable.
In the event that my primary server (Obiwan) goes down, the haproxy keepalived IP address is switched immediately (<1 second) to Solo and, if necessary finally Skywalker (i.e. I have two failover servers), and each of them is running an “exact copy” of every container I want hot-backed up from Obiwan. In practice, each instance is a maximum 15-30 minutes “old” as that’s how often I copy –refresh. They go live *instantly* when Obiwan goes down and can thus provide me with a very reliable self-hosted service. My containers are completely updated – links, downloads, files, absolutely EVERYTHING down to even the MAC address is identical (max 30 minutes old).
Is this perfect? No.
What I DON’T like about this is that the server can still be up to 30 minutes old – that’s still a window of inconvenience from time to time (e.g. as and when a server goes down and I am not home – it happens). Also, I have to pay attention if a BACKUP server container is actually changed during the primary server downtime – I have to figure out what’s changed so I can sync it to the primary instances on Obiwan when I fix the issues, because right now I only sync one-way (that’s a project for another day). But for me, I manage that risk quite well (I usually know when Obiwan is going down, and I get notifications anyhow, so I can stop ‘making changes’ for a few minutes while Obiwan e.g. reboots). My customers don’t make changes – they just download files, so no issues on back-syncing there.
What I DO like about this is that I can literally lose any two servers and I still have a functioning homelab with customer-visible services. Not bad!
In the earlier days, I have tried playing with lxd clustering, and ceph on my lxd servers to try more slick backup solutions that could be even more in sync in each direction. Nice in theory, but for me, it always gets so complicated that one way or another (probably mostly because of me!), it breaks. THIS SYSTEM I have come up with works because each server is 100% independent. I can pick one up and throw it in the trash and the others have EVERYTHING I need to keep my services going. Not shabby for a homelab.
Technically, I actually do EVEN MORE than this – I also create completely separate copies of my containers that are archived on a daily and weekly basis, but I will save that for another article (hint: zfs deduplication is my hero for that service!).
I love lxd, and I am comfortable running separate servers vs clustering, ceph and other “cool tec” that’s just too hard for me. I can handle “copy –refresh” easily enough.
I hope you find this interesting. 🙂
One question: how do you roll your backups? Let me know on twitter (@OGSelfHosting) or on mastadon (@[email protected]).
TLDR; SSH with public-private key is quite secure, but it relies on you keeping your private key secure – a single point of failure. OpenSSH allows the additional use of one-time passwords (OTP) such as those generated via google authenticator app. This 2FA option provides for “better” security which I personally think is a good practice for ssh via wide area network access (i.e. over the intenet), but truth be told it’s not always convenient because, out-of-the-box and with most online instructions, you also have to use it when on your local area network which should be much more secure than accessing devices via the internet. Herein I describe how to setup 2FA (most important) and also how to bypass 2FA when using ssh on home lan-to-lan connections, but to always require it from anywhere outside the lan. This means your daily maintenance on-site can provide easy access to servers (using just your ssh key) whilst still protecting them with 2FA from any internet access.
My instructions below work on a July 2022 fresh install of Ubuntu 20.04 server, with OpenSSH installed (‘sudo apt update && sudo apt install openssh-server’ on your server if you need to do this). I further assume right now that you have password access to this server, which is insecure but we will fix that. I also assume the server is being accessed from a July 2022 fresh install of Ubuntu Desktop (I chose this to try to make it easier – I can’t cover all distros/setups of course).
The instructions for by-passing lan are right at the end of this article, because I spend a lot of time trying to explain how to install google-authenticator on your phone/server (which takes most of the effort). If you already have that enabled, just jump to the END of this article and you will find the very simple steps needed to bypass 2FA for lan access. For anyone else who does NOT use 2FA for ssh, I encourage you to read and try the whole tutorial.
WARNING – these instructions work for me, but your mileage may vary. Please take precautions to make backups and practice this on virtual instances to avoid being locked out of your server! With that said, let’s play:
INSTRUCTIONS
Firstly, these instructions require the use of a time-based token generator, such as google’s authenticator app. Please download and install this on your phone (apple store and play store both carry this and alternative versions). We will need this app later to scan a barcode which ultimately generates one time passwords. The playstore app is located here. Apple’s is here, Or just search the app stores for ‘google authenticator’ and match it with this:
Install it, that’s all you need to do for now.
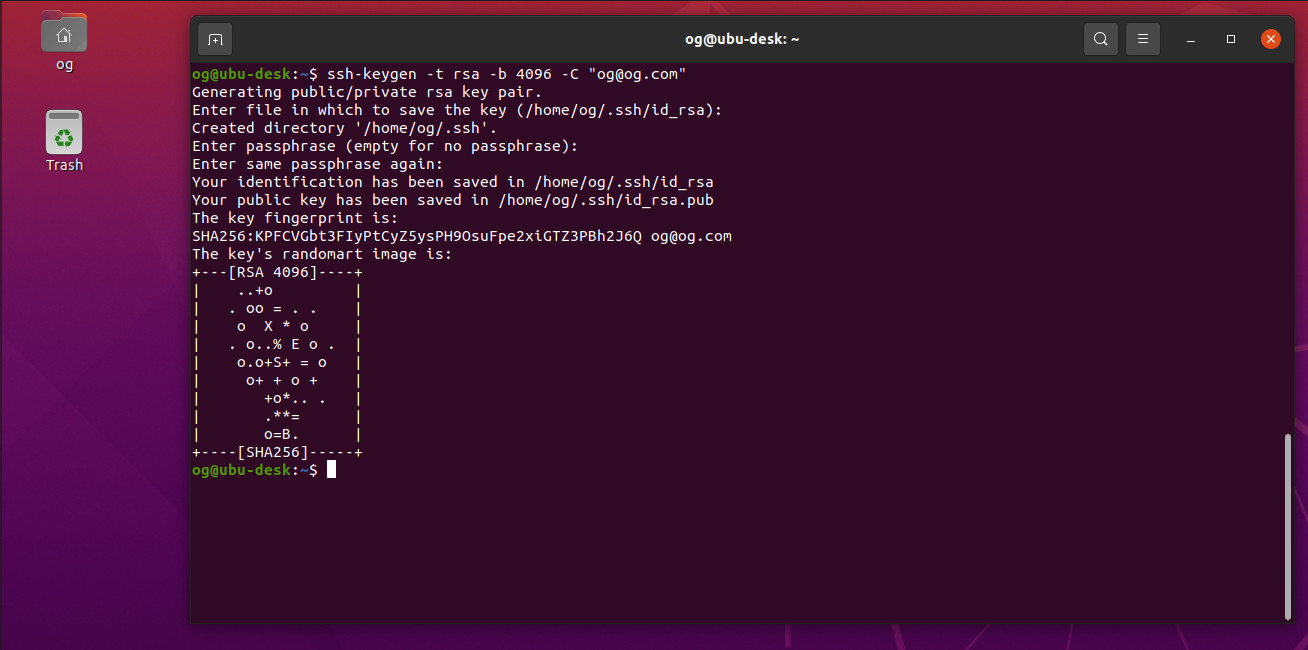
On your desktop, create an ssh key if required, e.g. for the logged-in user (in my case, username ‘og’) with an email address of [email protected]:
Enter a file name, or accept the default as I did (press ‘Enter’). Enter a passphrase for the key if you wish (for this demo, I am not using a passphrase, so I just hit enter twice). A passphrase more strongly protects your ssh key. You should see output like this:
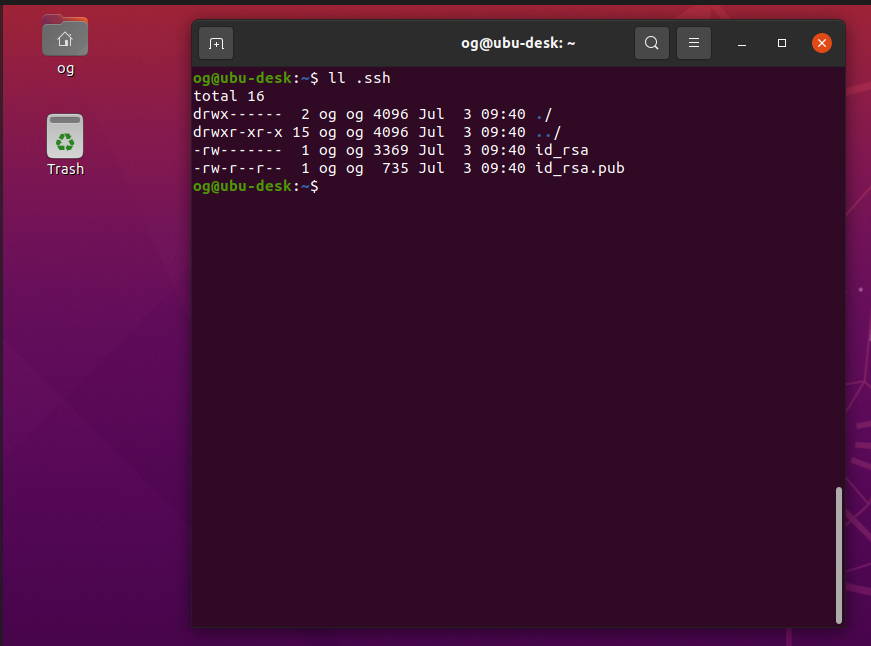
If you now check, you will see a new folder created called .ssh – let’s look inside:
id_ras is the PRIVATE key, id_rsa.pub is the PUBLIC key – we need both
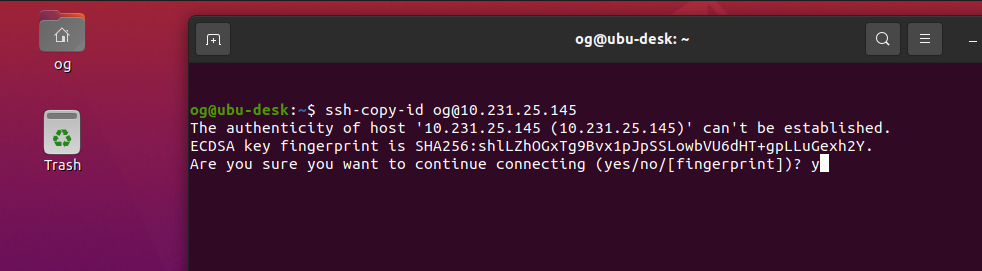
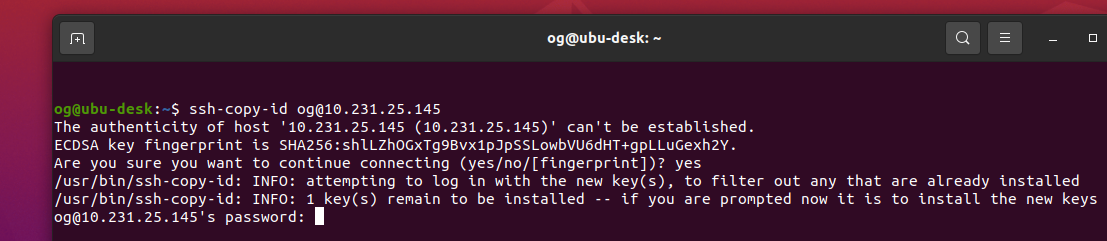
Now let’s copy the ssh key to our server. We assume our server is on ip 10.231.25.145, and your username is og in the commands below. Please change the IP and username for yours accordingly:
In my case, this was the first time I accessed this server via ssh, so I also saw a fingerprint challenge, so I was first presented with this, which I accepted (type ‘yes’ and ‘Enter’):
The server then prompts you for your username credentials:
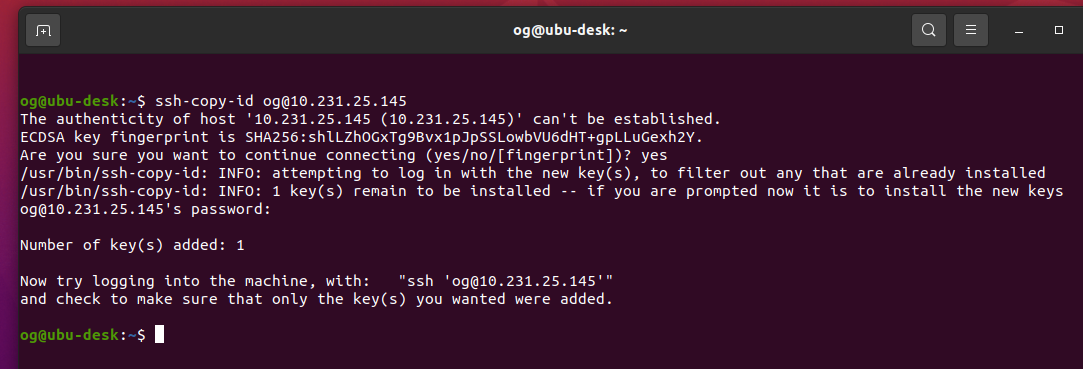
Enter your password to access the server then you will see this message:
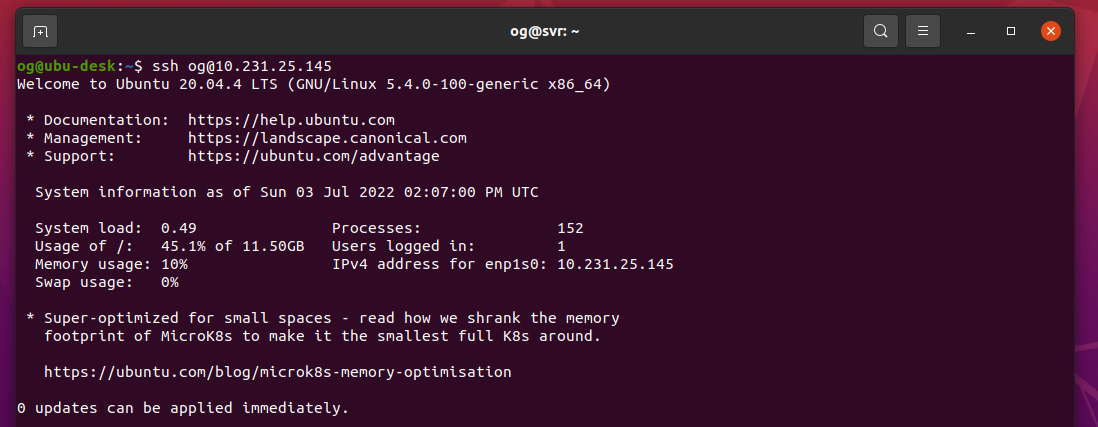
Prove it by logging in as suggested in the screen prompt that you have (in mine, it says ‘try logging into the machine, with ssh [email protected]’ – yours will be different), you should see something like this:
Stage 1 complete – your ssh key is now in the server and you have passwordless and thus much more secure access. Note, if you secured your ssh key with a password, you will be prompted for that every time. There are some options for making that more conveneient too, but that’s right at the very end of this article. Further note: DO NOT delete or change your ssh key as you may otherwise get locked out of ssh access for your server after you make additional changes per below, as I intend to remove password access via ssh to the server:
Log back into your server if required, then edit your ssh config file to make some basic changes needed for key and 2FA access:
sudo nano /etc/ssh/sshd_config
(Here is my complete file, including the changes highlighted in bold red):
# $OpenBSD: sshd_config,v 1.103 2018/04/09 20:41:22 tj
# This is the sshd server system-wide configuration file. See
# sshd_config(5) for more information.
# This sshd was compiled with PATH=/usr/bin:/bin:/usr/sbin:/sbin
# The strategy used for options in the default sshd_config shipped # with
# OpenSSH is to specify options with their default value where
# possible, but leave them commented. Uncommented options
# override the
# default value.
Include /etc/ssh/sshd_config.d/*.conf
#Port 22
#AddressFamily any
#ListenAddress 0.0.0.0
#ListenAddress ::
#HostKey /etc/ssh/ssh_host_rsa_key
#HostKey /etc/ssh/ssh_host_ecdsa_key
#HostKey /etc/ssh/ssh_host_ed25519_key
# Ciphers and keying
#RekeyLimit default none
# Logging
#SyslogFacility AUTH
#LogLevel INFO
# Authentication:
#LoginGraceTime 2m
#PermitRootLogin prohibit-password
#StrictModes yes
#MaxAuthTries 6
#MaxSessions 10
PubkeyAuthentication yes
# Expect .ssh/authorized_keys2 to be disregarded by default in future.
#AuthorizedKeysFile .ssh/authorized_keys .ssh/authorized_keys2
#AuthorizedPrincipalsFile none
#AuthorizedKeysCommand none
#AuthorizedKeysCommandUser nobody
# For this to work you will also need host keys in /etc/ssh/ssh_known_hosts
#HostbasedAuthentication no
# Change to yes if you don't trust ~/.ssh/known_hosts for
# HostbasedAuthentication
#IgnoreUserKnownHosts no
# Don't read the user's ~/.rhosts and ~/.shosts files
#IgnoreRhosts yes
# To disable tunneled clear text passwords, change to no here!
PasswordAuthentication no
#PermitEmptyPasswords no
# Change to yes to enable challenge-response passwords (beware issues with
# some PAM modules and threads)
ChallengeResponseAuthentication yes
# Kerberos options
#KerberosAuthentication no
#KerberosOrLocalPasswd yes
#KerberosTicketCleanup yes
#KerberosGetAFSToken no
# GSSAPI options
#GSSAPIAuthentication no
#GSSAPICleanupCredentials yes
#GSSAPIStrictAcceptorCheck yes
#GSSAPIKeyExchange no
# Set this to 'yes' to enable PAM authentication, account processing,
# and session processing. If this is enabled, PAM authentication will
# be allowed through the ChallengeResponseAuthentication and
# PasswordAuthentication. Depending on your PAM configuration,
# PAM authentication via ChallengeResponseAuthentication may bypass
# the setting of "PermitRootLogin without-password".
# If you just want the PAM account and session checks to run without
# PAM authentication, then enable this but set PasswordAuthentication
# and ChallengeResponseAuthentication to 'no'.
UsePAM yes
#AllowAgentForwarding yes
#AllowTcpForwarding yes
#GatewayPorts no
X11Forwarding yes
#X11DisplayOffset 10
#X11UseLocalhost yes
#PermitTTY yes
PrintMotd no
#PrintLastLog yes
#TCPKeepAlive yes
#PermitUserEnvironment no
#Compression delayed
#ClientAliveInterval 0
#ClientAliveCountMax 3
#UseDNS no
#PidFile /var/run/sshd.pid
#MaxStartups 10:30:100
#PermitTunnel no
#ChrootDirectory none
#VersionAddendum none
# no default banner path
#Banner none
# Allow client to pass locale environment variables
AcceptEnv LANG LC_*
# override default of no subsystems
Subsystem sftp /usr/lib/openssh/sftp-server
# Example of overriding settings on a per-user basis
#Match User anoncvs
# X11Forwarding no
# AllowTcpForwarding no
# PermitTTY no
# ForceCommand cvs server
AuthenticationMethods publickey,keyboard-interactive(END OF FILE)
Note there is a LOT MORE you can do to configure and secure ssh, but these changes (when completed - inc. below) will make for a much more secure installation than what you get 'out of the box'.
Now install the server version of google-authenticator on your server - this is what we 'syncronise' to your phone:
sudo apt install -y libpam-google-authenticator
Now configure authenticator by typing the following command and hitting 'Enter':
google-authenticator
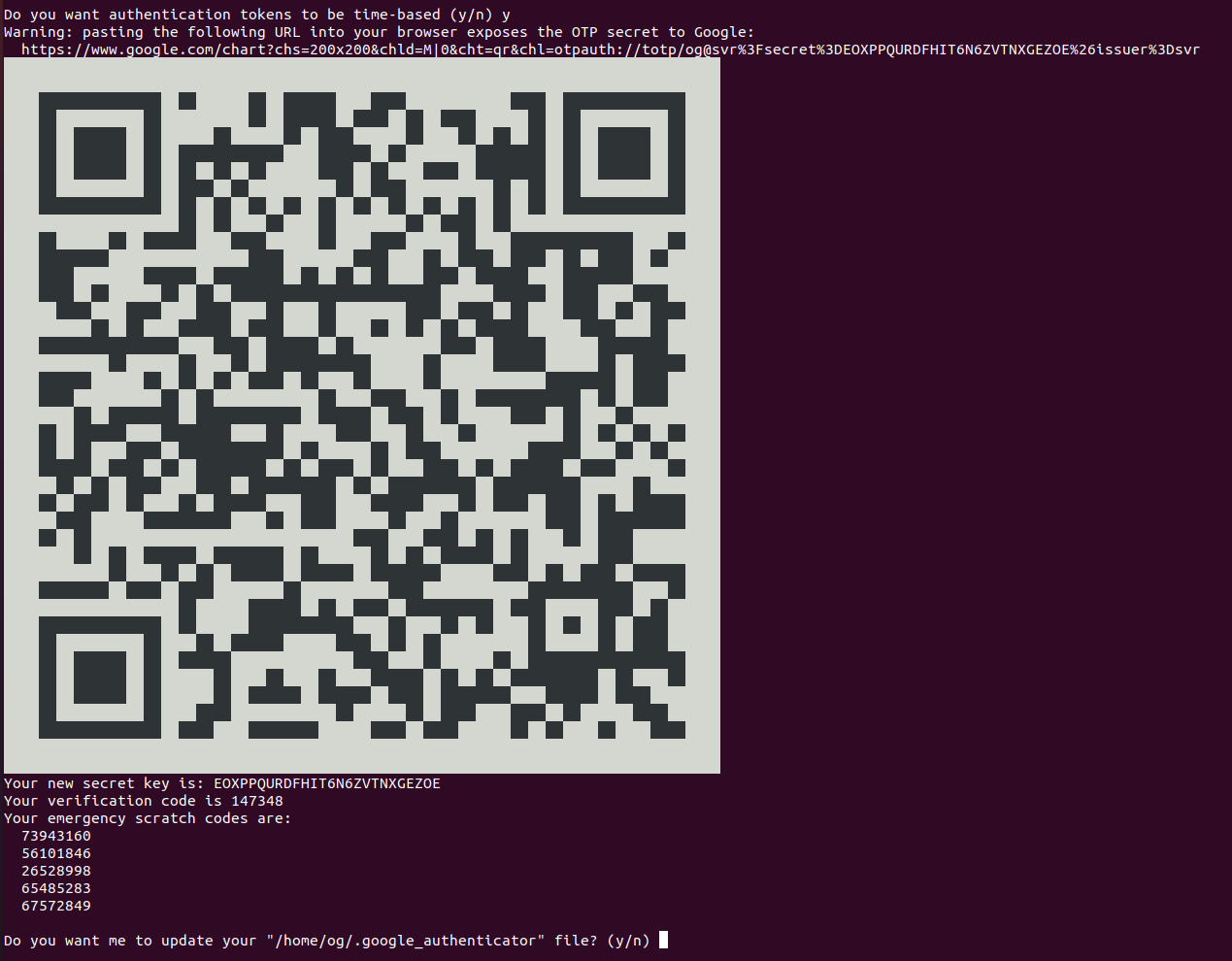
Enter 'y' at the first prompt and you will see somehing like this:
The QR code is your google authenticator 2FA key. Enter this into your phone app by opening the app and scanning the QR code generated on your screen. The authenticator app uses the above QR code (key) to generate seemingly random numbers that change every 30 seconds. This is our 2FA code and using it as part of your ssh login it makes it MUCH HARDER for someone to hack your ssh server.
PRO TIP: Also, take a screenshot of your QR code (i.e. the above) and save it in a very secure place (offline?) so you can re-create your 2FA credential if you ever e.g. lose your phone. It saves you having to reset everything, but keep it VERY SECURE (like your rsa private key).
Accept ‘y’ to update the google authenticator file. I accepted all the default prompts too, and that’s a pretty good setup so I recommend you do the same. Once you are done, you should see something like this:
Now edit the following file on your server:
sudo nano /etc/pam.d/sshd
Comment out the ‘@include common-auth’ statement at the top of the file by making it look like this:
# @include common-auth
(This disables the use of password authentication, which is very insecure, especially if you have a weak password). Then add these 2 lines to the end of the file: auth required pam_google_authenticator.so auth required pam_permit.so
Save the file. Now restart the ssh server using:
sudo systemctl restart ssh
Now open a NEW terminal window on our desktop (do not close the original window – we need that to fix any mistakes, e.g. a typo). Ssh back into your server using this second terminal window. If all has gone well, you will be prompted to enter the google-authenticator code from the app on your phone:
Enter the 2FA code from your smartphone google-authenticator app and hit enter, this should get you back at the terminal of your server, logged in SECURELY and using an SSH-key AND 2FA credentials. If all has further gone well, you will be greeted with your login screen – something like:
CONGRATULATIONS! You have now enabled 2FA on your server, making it much more secure against hackers. Your server is now much safer than the out-of-the-box method that uses a password only to secure a server. NOTE if you are unable to login, use the original terminal to edit your files and fix typo’s etc. DO NOT close the original terminal window until you have 2FA working, else you will lock yourself out of your server and will have to use a mouse, keyboard and monitor to regain access.
But we are not done yet – if you recall, I said we want to make this convenient, and this is the really EASY part. Log back into your server (if required) then re-open the /etc/pam.d/sshd file:
sudo nano /etc/pam.d/sshd
Add the following line above the prior two entries you made earlier (note that in my version below, the string wraps to two lines but it should all be on a single line):
So to be clear, the end of your file (i.e. the last three lines of /etc/pam.d/sshd) should look like this:
Save the file. Now create and edit the following file. This is where we will make this configuration work differently for lan vs wan access:
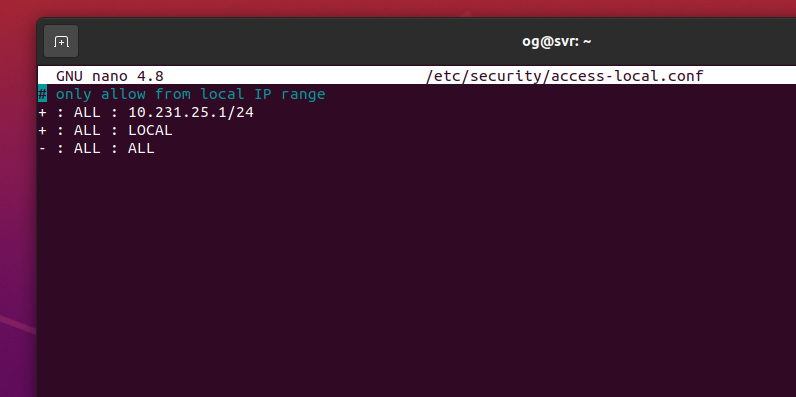
sudo nano /etc/security/access-local.conf
Enter something like this, but change the 10.231.25.1/24 IP range to your lan. For example, if your lan is 192.168.1 to 192.168.1.255, enter 192.168.1/24. Mine is 10.231.25.1/24, so I use the following
+:ALL : 10.231.25.1/24 +:ALL: LOCAL +:ALL:ALL
I know that looks a little…strange, but it will bypass 2FA requirements when the originating IP is as shown in line 1. My file looks like this:
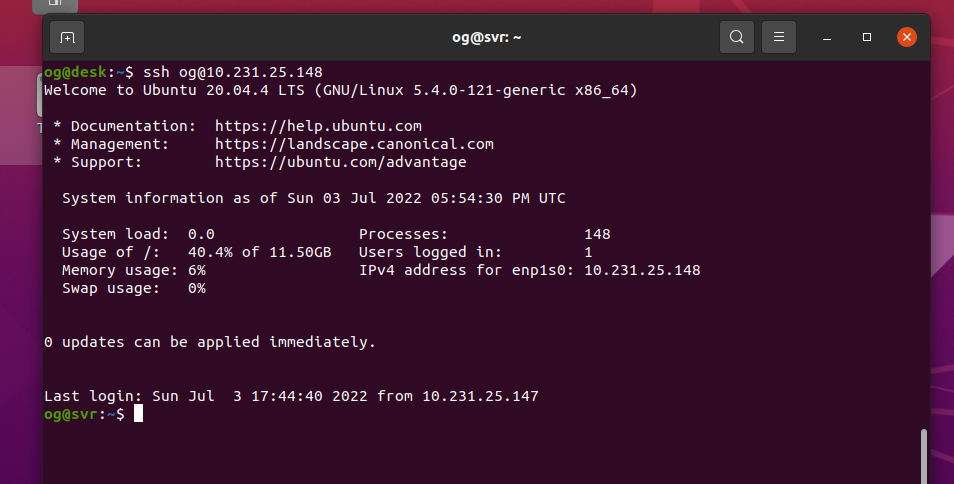
Save the file, quit your server then re-login to your server (no need to restart even the ssh-server – this works straight away). You are immediately greeted with your login screen – no 2FA credential is required:
So you are no longer asked for any 2FA key, but only because you logged in from your lan. That’s because the server knows you are accessing ssh from your lan (i.e. in my case, an address in the range 10.231.25/1 to 10.231.25.255 in the above example), so it will bypass the need for 2FA. If you try to login via any other ip range – say a wifi hotspot in a hotel, or indeed ANY different network you will need to enter your 2FA credentials in addition to having the ssh key of course (which you need for lan access too – i.e. the .ssh/id_rsa keyfile).
BONUS TIP – remember I touched on the use of passwords for rsa keys. They too are useful but can be “inconveneient” to re-type every time. There are password caching mechanisms for logins (google is your friend), but you can also make this “even more secure” and yet still very convenient for lan acccess by adding a password to the copy of your private rsa key that you use to access the server remotely, but dispense with that for the ssh key you use to access it locally.
I hope this tutorial helped. Comments very welcome and I will try to answer any questions too! I can be reached on @OGSelfHosting on Twitter.
I have operated a Nextcloud instance for several years. It has completely replaced DropBox, OneDrive and even Google Drive for me. However, my single-instances of Nextcloud have occasionally had downtime (power cuts, server issues and especially ‘administrator configuration fubars’). I have experimented with a Nextcloud failover service to try to improve mmy uptime, and it’s now in ‘experimental operation’.
At the present time, I now have TWO instances running on two different hardware platforms. Both instances run in a virtual environment. One, running on my new dual-EPYC server, is the primary instance intended to be in operation ‘all of the time’. The other, on a purpose-built server based on consumer hardware, is a mirror of the primary instance but theoretically is always hot and able to come online at a moments notice. If my primary server goes down, the backup takes over in about 1-3 seconds.
Primary Nextcloud container running on server1 (top right), backup on server2 (top left)
I rely upon two key software packages to help me make this happen: (1) lxd, which I use to run all my containers and even some of my vm’s (I suspect Docker would work equally well); and (2) keepalived, which provides me with a ‘fake’ IP I can assign to different servers depending on whether they are operational or not.
I am going to run this service with just two instances (i.e. one fail-over server). For now, both services are hosted in the same physical property and use the same power supply – so I do not have professional-grade redundancy (yet). I may add a third instance to this setup and even try to place that in a different physical location which would considerably improve robustness against power loss, internet outages etc. But that’s for the future – today I just finally have some limited albeit production-grade fail-over capability. I shall see if this actually makes my reliably better (as intended), or if the additional complexity just brings new problems that make things worse or at least no-better.
Server2 has kicked-in when I shutdown server 1.
A couple of additional details – I actually hot-backup both my Nextcloud server and a wordpress site I operate. As you can also see from the above image, I also deliberately change the COLOR of my Nextcloud banners (from blue to an unsubtle RED) just to help me realize something is up if my EPYC server goes down since I don’t always pay attention to phone notifications. I only perform a one-way sync, so any changes made to a backup instance will not be automatically regenerated on the primary server as/when it comes back online after a failure. This is deliberate, to reduce making the setup too complicated (which could otherwise not go unpunished!). A pretty useful feature: my ENTIRE Nextcloud instance is hot-copied – links, apps, files, shares, sql daabase, ssl certs, user-settings, 2FA credentials etc. Other than the color of the banner ( and a pop-up notification), the instances are ‘almost identical’*. Lxd provides me with this level of redundancy as it copies everything when you use the refresh mode. Many other backup/fail-over implemetations I have explored in the past do not provide the same level of easy redundency for a turn-key service.
(*) Technically, the two instances can never be truly 100.0000000…% identical no matter how fast you mirror an instance. In my case, there is a user-configurable difference between the primary server and the backup server at the time of the fail-over coming online. I say user-cobfigurable because this is the time delay for copying the differences between server1 and server2. I configure this via the scheduling of the ‘lxc copy –refresh’ action. On a fast network, this can be as little as a minte or two, or potentially even faster. For my use-case, I accept the risk of losing a few minutes worth of changes, which is my maximum risk for the benefit of having a fail-over service. Accordingly, I run my sync script “less frequently” and as of now, it’s a variable I am playing with vs running a copy –refresh script constantly.
If anyone has any interest in more details on how I configure my fail-over service, I’ll be happy to provide details. Twitter: @OGSelfHosting
How to luks-encrypt and auto-unlock a drive used for zfs storage
I have seen some onlne articles that misleadingly state that you can’t have a luks layer on zfs used in an lxd pool, because the pool will disappear after a reboot. Such as this github posting here. The posting is unfortunate because I think the question and answer were not aligned and so the suggestion that comes from the posting is that this can’t be done and the developers are not going to do anything about it. I think they each missed each others points.
Fact is, creating a zpool out of a luks drive is quite easy – be it a spinning harddrive, an SSD or an NVMe. I will walk though an example of creating a luks drive, creating a zfs zpool on top of that, and having the drive correctly and automatically decrypt and get imported into zfs at boot. The resultant drive has data FULLY ENCRYPTED at rest (i.e. in a pre-booted or powered off state). If someone takes your drive, the data on it are inaccessible.
But first….
WARNING WARNING – THE INSTRUCTIONS BELOW WILL WIPE A DRIVE SO GREAT CARE IS NEEDED. WE CANNOT HELP YOU IF YOU LOSE ACCESS TO YOUR DATA. DO NOT TRY THIS ON A PRODUCTION SERVER. EXPERIMENT ON DRIVES THAT ARE EITHER BARE OR CONTAIN DATA YOU DO NOT VALUE ANYMORE. SEEK PROFESSIONAL HELP IF THIS IS UNCLEAR, PLEASE!
Now, with that real warning out of the way, let’s get going. This tutorial works on linux debian/ubuntu – some tweaking may be needed for RH and other flavors of linux.
I will assume the drive you want to use can be found in /dev as /dev/sdx (I deliberately chose sdx as it’s less likely you can make a mistake if you cut and paste my commands without editing them first!). Be ABSOLUTELY CERTAIN you have identified the right designation for your drive – a mistake here will be … very unfortunate.
We need to first create our luks encryption layer on the bare drive.
Last warning – THE INSTRUCTIONS BELOW WILL ABSOLUTELY WIPE YOUR DRIVE:
sudo cryptsetup luksFormat /dev/sdx
The above command will ask for your sudo password first then it will ask for the encryption password for the disk. Make it long and with rich character depth (upper/lower case, numbers, symbols). Note that the command luksFormat contains an upper case letter. It’s common in all the commands – so be precise in your command entry.
Now immediately open the new encryted disk, and give it a name (I am using sdx_crypt):
sudo cryptsetup luksOpen /dev/sdx sdx_crypt
You now have access the this disk in /dev/mapper (where luks drives are located). So we can create our zpool:
You can of course change our zpool parameters, obviously including the name, to your liking. But this is now a working luks encrypted zpool. You can use this in e.g. lxd to create a fully at-rest encrypted data drive which is protected in the case of e.g. theft of hardware.
But we are not quite done yet. Unless you enjoy typing passwords into your machine at every boot for every encrypted drive then we need one more additonal but technically ‘optional’ step – to automatically unlock and zfs-import this drive at boot (optional because you can enter this manually at every boot if you are really paranoid).
We do this by creating a file (similar to your password), but we store it in a /root folder, making it accessible only to root users. We use this file content to act as a password for decrypting the luks drive:
The above two commands create a random binary file and store it in the folder /root. This file is not accessible to anyone without root privileges. We now firstly apply this key file to our encrypted disk:
(You will be asked to enter a valid encryption key – it uses this to add the binary file to the luks disk header. Use the strong password you created when you formatted the drive earlier).
So now, your drive is luks encrypted with your password AND with this file. Either can decrypt the drive.
Now all we need to do is add another entry to our /etc/crypttab file, which is what linux uses at boot to decrypt and mount files. So let’s get a proper identity for our drive – somthing that will not change even if you move the disk to a different computer or plug it into a different sata port etc.:
sudo blkid
This command will bring up a list of your atatched drives and their block id’s. E.g, here’s an abridged version of mine:
What you need to look for is the entry that matches your luks drive, it will look something like this – note that there are two entries of interest, but we only need ONE:
We want the /dev/sdx line (intentionally bolded, above in the example output). Do NOT use the /dev/mapper/sdx_crypt UUID. Carefully copy the UUID string (‘d75a893d-78b9-4ce0-9410-1340560e83d7’, in the above example). Now, open the system crypttab file as root and add an entry like below, but using your exact and full UUID from your /dev/sdx blkid command output:
sudo nano /etc/crypttab
Add the following at the bottom of the file:
#Our new luks encrypted zpool drive credentials #Note this gets automatically unlocked during the boot cycle #And then it gets automatically imported into zfs and is immediately #available as a zfs zpool after the system bootup is complete. #Add the following as one continuous line then save, quit & reboot:
Now reboot. Assuming your boot partition is encrypted, you will have to unlock that as normal, but then the magic happens: linux will read the crypttab file, find the disk and decrypt it using the /root/.sdx_keyfile, then pass the decrypted drive (called sdx_crypt) to zfs who will be able to import and access the zpool as normal. no delays, no errors – it just WORKS!
If you want to be 100% sure you really have an encrypted drive then, ether unmount and lock the drive locally (in which case your zpool will disappear). Or, for a more extreme test, power off your system, take the drive out and examine it on another compter – you will see the drive is a luks drive. You cannot read any data on it unless you decrypt it, and you need that /root/.sdx_keyfile or the password. At rest, powered off, your data is secure. Put the disk back into your computer (any sata port – we use credentials that identify this specific drive) and boot up – voila, your zpool will reappear.
Note that this method is very secure. It will be impossie to access this disk without unless you either have the very strong password you used to encrypt the drive or the /root/.keyfile. The latter can only be read by root-level user.
This is how we roll luks. Literally ALL of our servers, desktops and drives are setup this way. It does require the manual unlocking of the boot drive after every bare metal machine reboot, but we can do that even remotely. We think that the peace of mind for protecting our data are worth this inconvenience. (I can show how I decrypt the root partition over ssh in another article – let me know if that interests you). Good luck with your luks’ing.
TLDR; I built a dual-cpu EPYC-based server in a tower case for home networking – and it’s really cool, literally!
I have spent some time over the last few days assembling, configuring and testing my over-the-top home-server, the heart of which has dual first-generation AMD Naples 32-core EPYC 7601 CPU’s. This posting is an initial quick-look at my system – just to get something out there in case others are looking at doing something similar – there’s not a lot of homelab information on dual-core Epyc setups (probably because they are way in excess of the capabilities you need for average homelab workloads).
I have a major goal for this build of being a capable but QUIET system that fits in a home environment in a Tower with some RGB bling so it looks cool too. Hardware wise the system consists of:
Two used AMD EPYC 7601 CPU’s – 32 cores each, 2.2 GHz base clock and up to 3.2 GHz max boost clock depending on the load/usage
A used SuperMicro H11DS i -NT motherboard – highlights
Courtesy of one of the PCIE 3.0 x16 lane that’s holding a quad NVME adapter:
Quad M.2 NVME SSD to PCI-E 4.0 X16 Adapter – 3rd party accessory
One Samsung EVO 4TB SSD
Two Kingston 256GB NVME (one for the OS – Ubuntu 20.04 server, one for my Timeshift backups)
Two x Noctua NH-U14S TR4-SP3 cooling fans
All of this is housed in a Fractal Torrent E-ATX RGB case which has 2 x 180mm and 3x 140mm regular cooling fans. I went with Fractal and Noctua because I wanted very low operational noise and effective cooling, and I went with a Tower configuration and upgraded to RGB because this sits in my home office and we at home want this to look cool as it’s visible in the home space.
Back in the distant day of 2018, the CPU’s alone cost over $4k each, but AMD have had two generational releases of EPYC since then – Rome and Milan, causing the price of Naples hardware to plummet as is common. I thus got these two flagship Naples CPU’s and motherboard for $1.3k on EBay – sourced from China so I wasn’t sure what to expect, but it turns out to be exactly what I hoped I had bought. As an old-guy, getting my hands on an overpowered 64 core monster like this seems amazing given that I started with the most basic 8-bit computers that cost an arm and a leg back in the early 1980’s. For this build, I had to buy drives, memory, power supply, case etc. (all of which were new) so the total build cost is more than I want my wife to know, but I am very happy with how it is coming on.
Assembly of the system has been straighforward although it took longer than I initially expected because I needed the odd additional cable and such, but nothing that impacted actual performance (more for aesthetics). Note that the motherboard does not have connectors for some of the case front ports (usb c etc.). I will likely leave these dead, but you can buy an add on pcie card that can connect to these if required (I just run power and ethernet to my server – no keyboard, monitors or usb devices. I can access the machine via the IPMI device which is…awesome to a guy coming from using consumer motherboards for running servers)
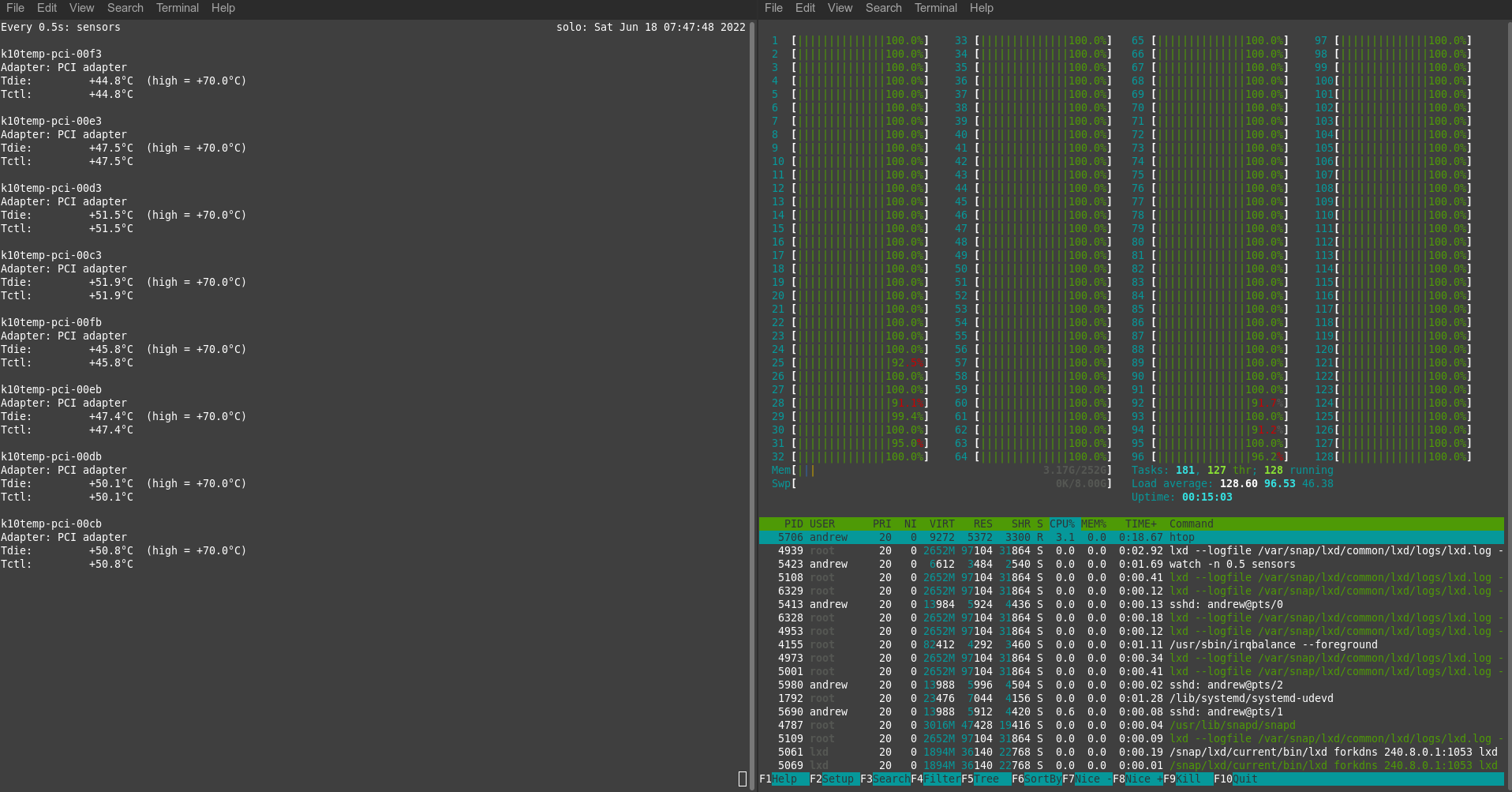
Performance wise this has yet to be put through sustained trials, but I have already been testing and recording the power consumption (using a COTS power meter) and system temperatures under no-load and all-core loading (via simple stress-ng, htop and sensors command line utilties on Ubuntu 20.04).
Here’s a quick-look summary of some of the stress/temperatures/power-draw I am seeing in this setup:
No load – drawing less 100 Watts of power from the outlet – pretty reasonableTemperatures under no-load conditions (CPU’s 2 and 1 are respectively k10temp-pci-00e3 and -00d3). Very respectable temperatures in an ambient environment of ~24C.Power consumption from the outlet at max load (all 64 cores @ 100%, via stress-ng command line tool running on Ubuntu)This shows temperatures of all 65 cores (128 threads) at max loading – very respectable
The above is a simple summary, but it shows the excellent ventilation and cooling fans of the Torrent and the Noctua CPU coolers can easily tame this system – 48-50C for the CPU’s is well within their operating temperatures, and I may actually get better than that once I setup some ipmi fan profiles to increase system cooling under such high CPU loads. the above results were obtained under one of the standard supermicro IPMI fan profiles (“HeavyIO”), which is not especially aggressive. Noise wise, I can’t hear this system at all under ambient conditions, and barely under load. I may try to quantify that once I have everything setup.
Under load, the CPU’s do not overheat but it quickly raises the ambient temperature of my workspace a few degrees as notably warmer air emerges from the rear vents of the Fractal Torrent (I may need to beef up my AC…). I consider this just stunning cooling performance from the Torrent/Noctua’s.
Temperatures and power draw will increase as I finish out my build (more hardware/drives), but I can already see that the viability of this server setup in a Tower case is very positive.
I will use this system, once it’s finally ‘production ready’ to be the primary server for my virtualized home services.
Acknowledgements:
I spent many an hour scouring the web looking for Epyc home server / tower builds before I pulled the trigger on this used hardware. For those looking to do something equally crazy, note that there’s not a lot of information out there. Wendell at level One Tech has some excellent videos some of which go back to Epyc first-gen (e.g. here and here). Jeff at Craft Computing has several excellent videos on his Epyc home servers (e.g. here). Finally, Raid Owl has an informative and entertaining video on a more modern setup too (here). Thanks to all of you for the free, informative and entertaining content you provide! 🙂
If you have any questions, you can reach me on Twitter – Andrew Wilson, @OGSelfHosting
Welcome! My name is Andrew Wilson, and I run & self-host this site.
Self-hosting software/services is neither simple nor easy, but it is simple-enough and easy-enough for even an Old Guy to do it. It’s what I do, and I plan to use this site to blog my self-hosting journey.
This is my over-the-top hardware running all of my home services. It’s a dual cpu based, first-gen EPYC server home build in a Tower Case. More power than I can possibly use, delivered whisper quiet, even under load.
I operate several services that I have come to appreciate and rely upon, and as I am now a stones-throw away from retiring from my day-job, I plan to learn more about (i) self-hosting software services, (ii) build/operate and maintain my hardware, (iii) try to put it all together in a manner that reduces my exposure to hackers and bad-actors and (4) have FUN doing all this!
I also hope to post tutorials to share some of what I have learned on the way in the hope they can help folks who, like me, don’t have all the answers. 🙂
Find me on Twitter – Old Guy, Self-hosting – @OGSelfHosting
My home network runs via a vitualized instance of pfSense. and is supported by two Mikrotik switches that provide me with 10G network connectivity between my physical; servers.
Monetizing our private information is the primary, if not sole strategy of many large corporations that provide ‘information services for free’. facebook, Microsoft, Google, Yahoo and too-many-to-list companies are constantly tracking, compiling and collating everything they know about us. So that in fact, they probably know more than anyone about you as an indivudal. And they rent or sell this information to, well, anyone with a credit card.
If you participate in the modern digital world, it’s not easy to eliminate all of those monetizing services. But there are some things you can do to reclaim some of your privacy. This site has been set-up by me so I can provide some insights to my (continuing) journey to self-host services I like to use, and which helps me reclaim some of my privacy.