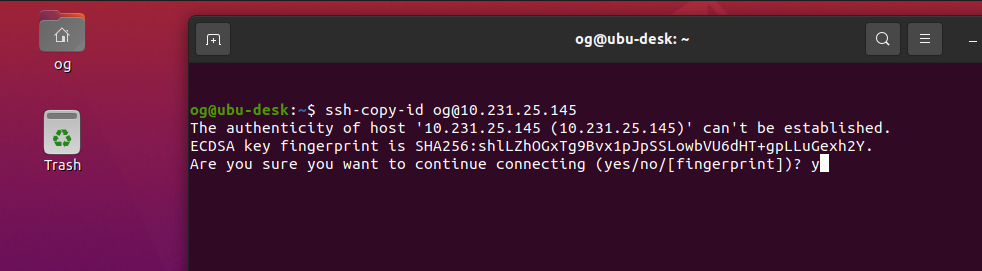
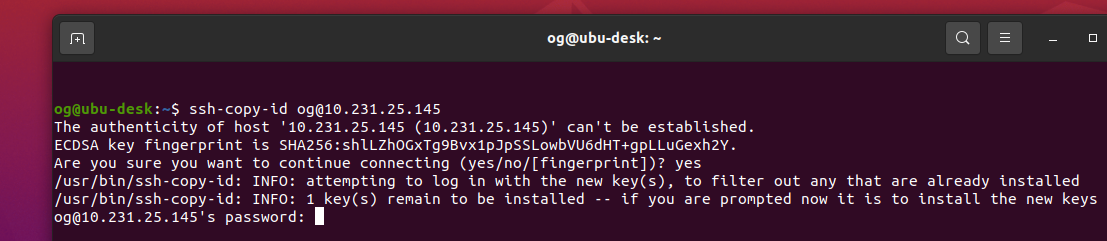
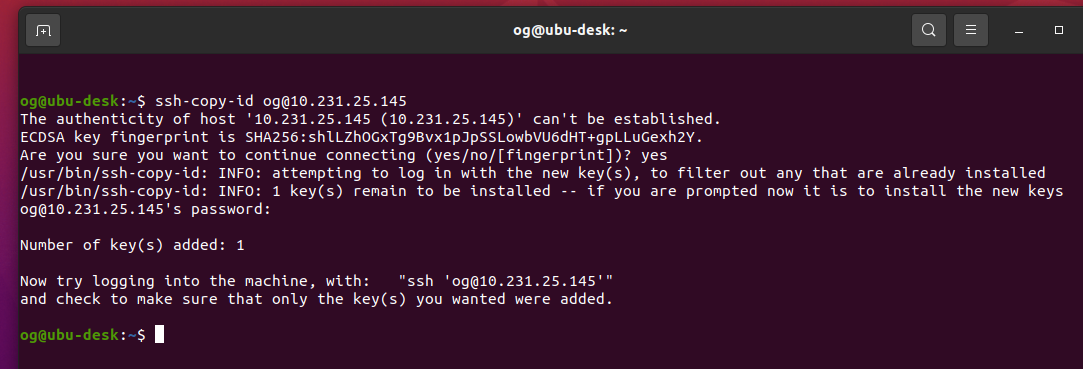
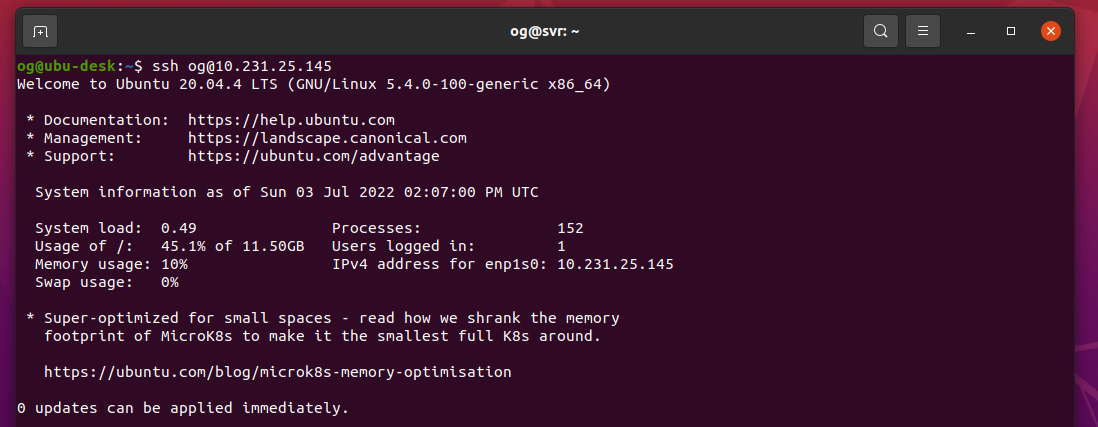
People who know me know I am a huge fan of virtualization using Cannonical’s lxd. I have been using lxd to create self-hosted web-facing lxc containers since 2016 (when lxd was running as version 2), with high (albeit imperfect) uptime. Over this period, I have added additional computing resources to my home network to improve uptime, user-experience, improved availability and overall performance (I’m a geek, and I like home network play as a hobby). One of the most important asset classes has been Nextcloud, my single most important self-hosted instance that helps me retain at least some of my digital privacy and to also comply with regulations that apply to digital information stored and used as part of my chosen career. I operate two instances of Nextcloud – one for work, one for personal. It’s been a journey learning how to configure them and keep them performing as optimally as I can get them.
I thought it might be good to document some of the methods I use to configure and maintain high availability of my self-hosted services, including Nextcloud. In the hopes that others might learn from this and maybe adopt/adapt to their own needs. I muddy the lines a bit between ‘backup’ and ‘high-availability’ because the technique I use for one, I also sort-of use for the other (that will become clearer below I hope). I backup not just my two Nextcloud instances using the method below, but also this web site and several other services I rely upon (about 11 critical containers as of today, growing slowly but steadily).
Using my high-availability/backup method actually makes it really hard for me to not be online with my services (barring electrical and ISP outages – like many, I don’t have much protection there). I don’t guarantee to never have problems, but I think I can say I am guaranteed to back online with like 99-100%+ of my services even if my live server goes down.
Firstly, for the majority of my self-hosted services, I run them mostly under lxd. Specifically as lxd containers. These are very fast and, well, completely self-contained. I tend to use the container for everything – including the storage requirements the container needs. My Nextcloud containers are just shy of 400GB in size today (large, unwieldy or so you would think), but most of them are just a few GB in size (such as this web site). If I can’t containerize a service, I use a virtual-machine (vm) instead of a container. Seldom though do I use lxd vm’s, I typically use virt-manager for that as I think it’s better suited. My Nextcloud instances run in lxd containers. When I first started using Nextcloud, I had one (small) Nextcloud container running on just one server. If it went down, as it did from time to time (almost always “operator error” driven), I had downtime. That started to become a problem, especially as I started sharing project files with customers so they needed links to just WORK.
So, even several years ago, I started looking at how to get good backups and high availability. The two seemed to be completely different, but now my solution to both is the same. Back then, there was no “copy –refresh” option (see later), so I was left trying to sync ever-growing containers to different machines as I built up my physical inventory. I repurposed old laptops to run as servers to give myself some redundancy. They worked. Well they half worked, but even then I still had blackouts that were not because of ISP or power-utility issues – they were my server(s) not working as I intended them to. My system has evolved substantially over the years, and I am now feeling brave enough to brag on it a little.
For my home network, I run three independent hot servers “all the time” (these are real machines, not VM’s). I have two proper servers running EPYC processors on Supermicro motherboards with way too much resources (#overkill), and I also have a server that’s based on consumer components – it’s really fast, not that the others are slow. Each server runs Ubuntu as the Operating System. Yes that’s right, I don’t use proxmox or other hypervisor to run my vm’s – everything is run via virtualizion on Ubuntu. Two of my live physical servers run Ubuntu 20.04, one runs 22.04 (I upgrade very slowly). In fact, I also run another local server that has a couple of Xeon processors, but I just use that for experiments (often wiping and re-installing various OS’s when a vm just won’t do for me). Finally, but importantly, I have an old System76 Laptop running an Intel i7 CPU and 20GB ram – I use this as a very (VERY) remote backup server – completely different network, power supply, zip code and host-country! I won’t go into any more details on that, but it’s an extension of what I do locally (and lxc copy –refresh is KEY there too – see later). LOL. Here’s some details of my current home servers for the curious:
| Server Name | CPU | RAM |
| Obi-wan Kenobe | Dual EPYC 7H12’s | 512 GB ECC x 3200MHz |
| Han Solo | Dual Epyc 7601’s | 256GB ECC x 2600 MHz |
| Skywalker | Ryzen 3900X | 128GB ECC x 3200 MHz |
| Darth Vader | Intel i7-7500U | 20GB non-ECC x 2133MHz |
| Dooku | Dual Xeon 4560’s | 24GB ECC x 1600 MHz |
The above servers are listed in order of importance to me. Obi-Wan Kenobe (or ‘obiwan’ per the actual /etc/hostname) is my high-end system. AMD EPYC 7H12’s are top of the line 64-core EPYC ROME CPU’s. I got mine used. And even then, they weren’t terribly cheap. Complete overkill for self-hosting but very cool to play with. Here’s my main ‘obiwan’ Epyc server:

Each of the servers Obiwan, Solo and Skywalker run lxd 5.0 under the Ubuntu OS (i.e the latest stable LTS version of lxd, not just the latest version), and each of them are using NVMe storage for the primary lxd default zpool for the containers:
zpool status lxdpool
pool: lxdpool
state: ONLINE
scan: scrub repaired 0B in 00:16:54 with 0 errors on Sat Mar 11 19:40:55 2023
config:
NAME STATE READ WRITE CKSUM
lxdpool ONLINE 0 0 0
nvme2n1_crypt ONLINE 0 0 0
nvme3n1_crypt ONLINE 0 0 0errors: No known data errors
Each of these lxd zfs storage pools is based on 2TB NVMe drives or multiples thereof. The lxd instance itself is initialized as a separate, non-clustered instance on each of the servers, each using a zfs zpool called ‘lxdpool’ as my default backing storage and each configured with a network that has the same configuration in each server. I use 10.25.231.1/24 is the network for the lxdbr0. This means I run three networks with the same IP as subnets under my lab.:
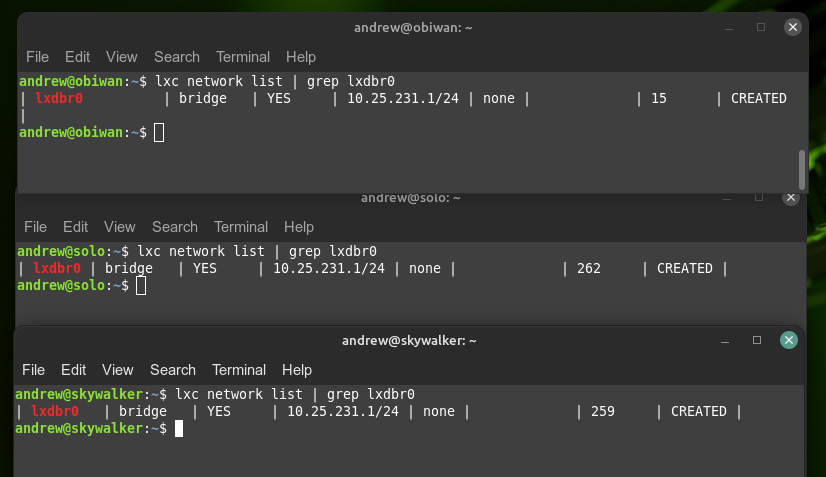
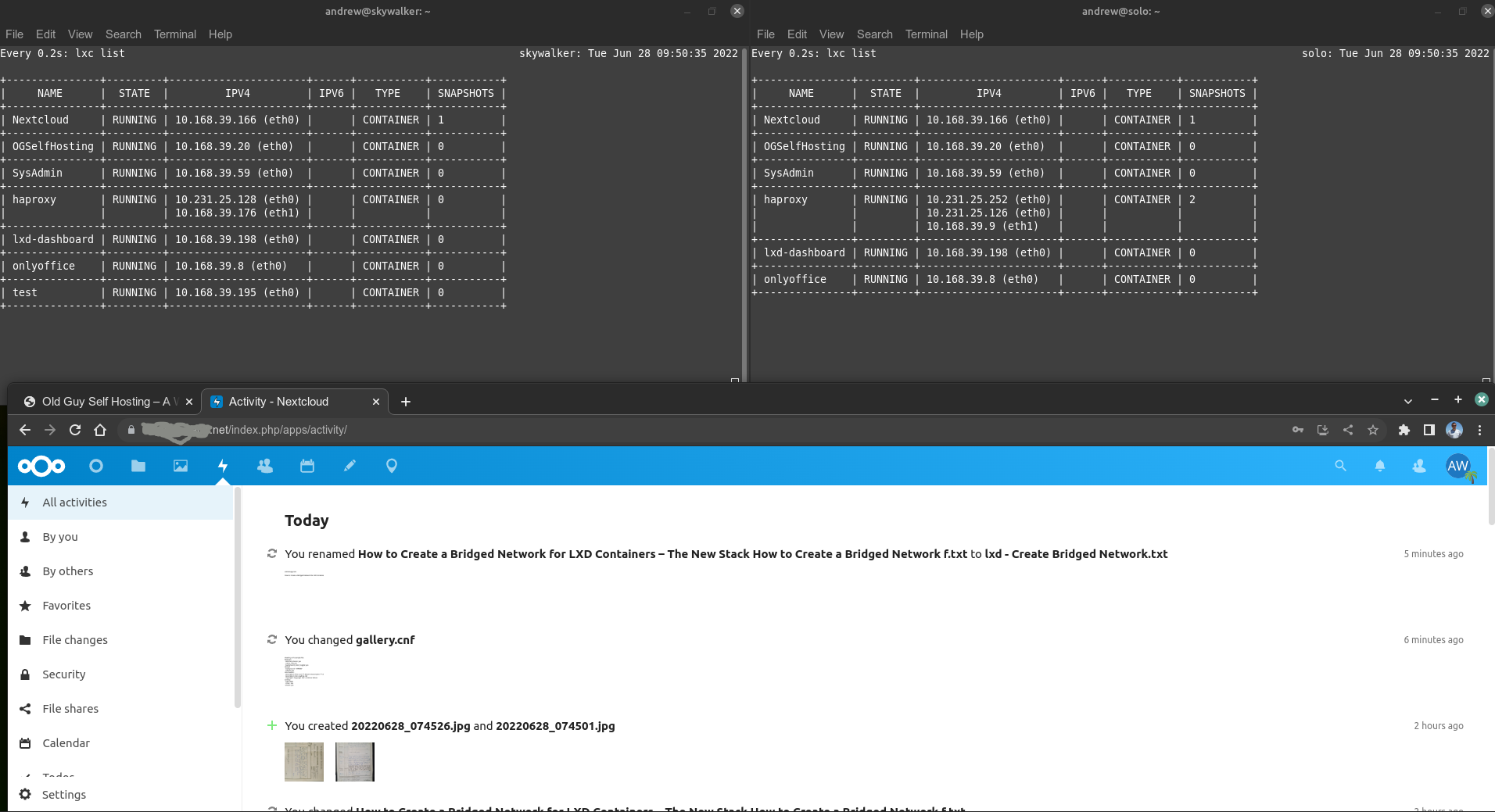
This is very deliberate on my part as it allows me to replicate containers from one instance to another – and to have each server run the same container with the same ip. Since these are self-contained subnets, there’s no clashing of addresses, but it makes it easy to track and manage how to connect to a container, no matter what server it is on. I host several services on each server, here’s some of them, as they are running on each server now:
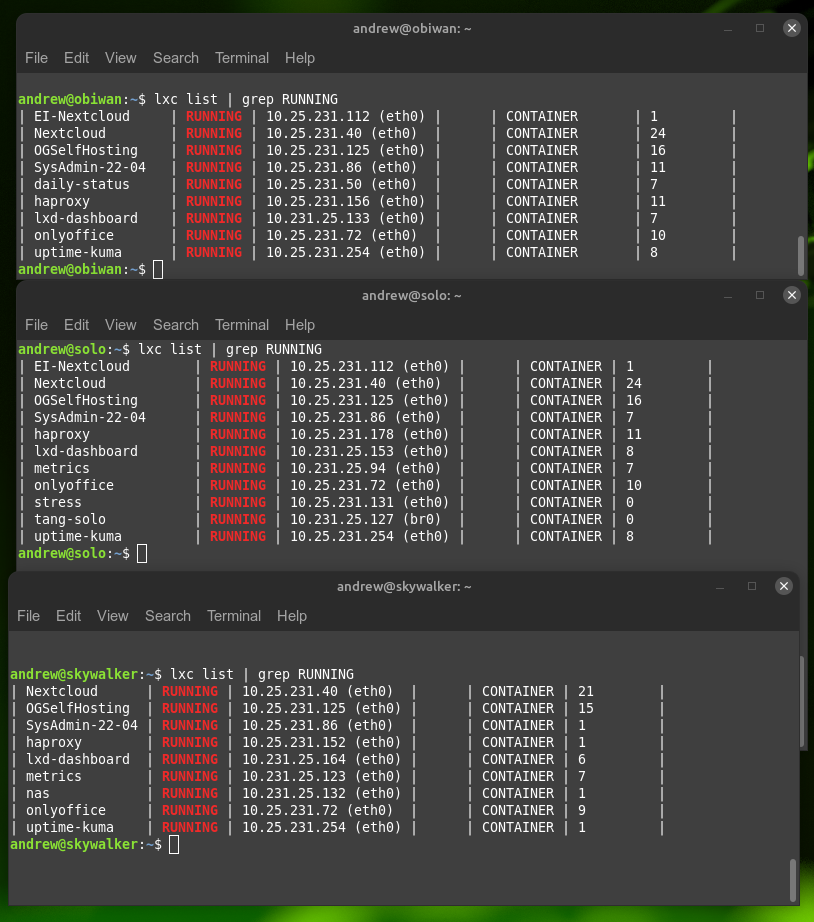
So to be clear, most (not all) of the containers have the exact same IP address on each server. Those are the ones I run as part of my three-server fail-over high availability service.
My haproxy container is the most unique one as each of them is in fact configured with three IP addresses (only one is shown above):
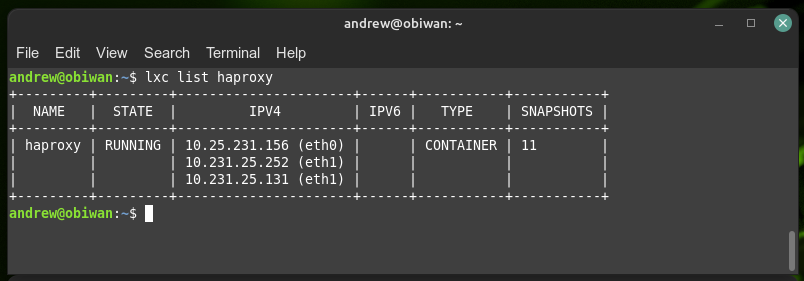
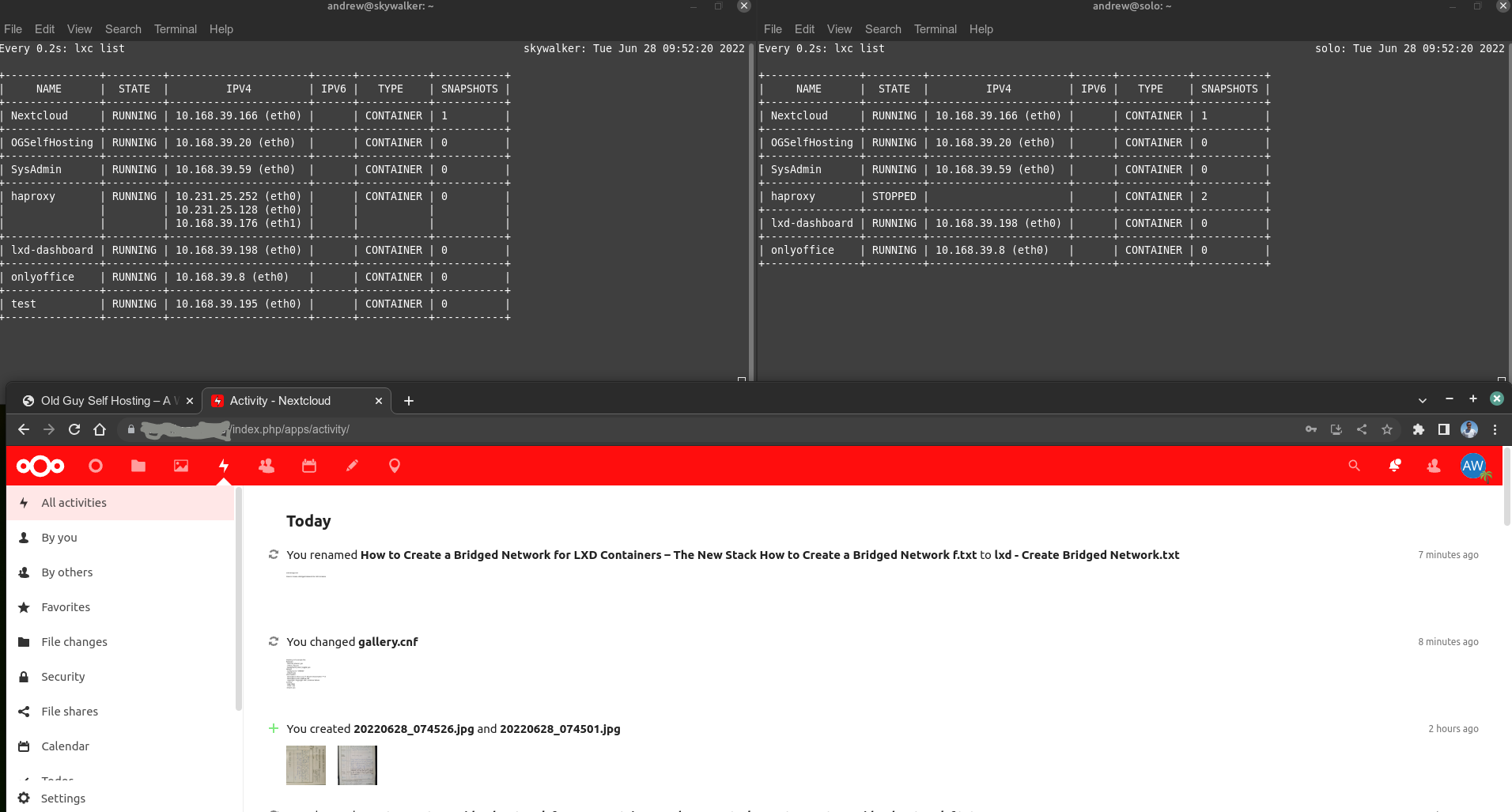
This is because my haproxy is my gateway for each lxd vm/container on each of the servers. If a web service is called for, it all goes via haproxy on the physical server. Note that two of the IP’s are from the same are from DHCP on my home LAN (10.231.25.1/24), whereas my servers each have their lxd networks configured using lxd DHCP from 10.25.231.1/24 (I chose to keep a similar numbering system for my networks as it’s just easier for me to remember). Importantly, my home router sends all port 80/443 traffic from www to whatever is sitting at IP 10.231.25.252. So that address is the HOT server, and it turns out, it’s very easy to switch that from one live server that goes down, immediately to a stand-by. This is keep to my high availability.
The 10.231.25.131 is unique to the Obiwan haproxy container, whereas 10.231.25.252 is unique to the HOT instance of haproxy via keepalived. On each of the other two hot servers, they are also running keepalived and they have a 10.231.25.x IP address. They ONLY inherit the second, key ip address of 10.231.25.252 if Obiwan: goes down – that’s the beauty of keepalived. It works transparently to me to keep a hot instance of 10.231.25.252 – and it changes blindingly fast if the current hot instance goes down (it’s a bit slower to change back ~5-10 seconds, but I only need one fast way so that’s cool).
So, if Obiwan goes down, one of my other two servers pick up the 10.231.25.252 IP *instantly* and they become the recipient of web traffic on ports 80 and 443. (Solo is second highest priority server after Obwan, and Skywalker is my third and final local failover). And since each server is running a very well synchronized copy of the containers running on Obiwan, there’s no disruption to services – virtually, and many times actually, 100% of the services are immediately available if a fail-over service is being deployed live. This is the basis for my lan high-availability self-hosted services. I can (and sometimes have to) reboot servers and/or they suffer outages. When that happens, my two stand-by servers kick in – Solo first, and if that goes down, Skywalker. As long as they have power. Three servers might be overkill for some, but I like redundancy more than I like outages – three works for me. Two doesn’t always work (I have sometimes had two servers dead a the same time – often self-inflicted!). Since I have been operating this way, I have only EVER lost services during a power cut or when my ISP actually goes down (I do not attempt to have redundancy from these). I’d say that’s not bad!
Here is a short video demonstrating how my high-availability works
So how do I backup my live containers and make sure the other servers can take over if needed?
- Firstly, even though I don’t use lxd clustering, I do connect each of the other two independent lxd servers to Obiwan, via the ‘lxd remote add’ feature. Very very cool:
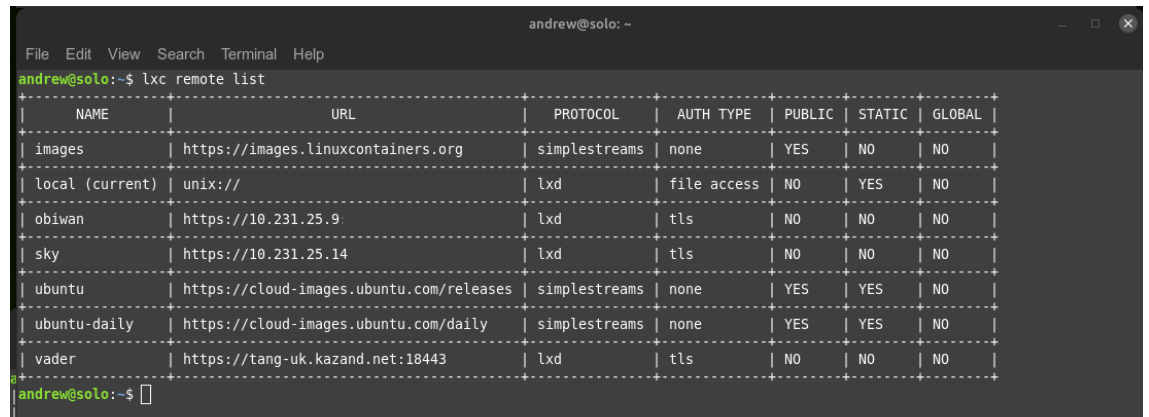
2. Each lxd server is assigned the same network address for the default lxdbr0 (this is important, as using a different numbering system can sometimes mess with lxd when trying to ‘copy –refresh’).
3. Each server also has a default zfs storage zpool called ‘lxdpool’ (this is also important). And I use the same backging storage as sometimes I have foound even that to behave oddly with copy –refresh actions.
4. Every X minutes (X is usually set to 30, but that’s at my choosing via cron) I execute essentially the following script at each of Solo and separately at Skywalker servers (this is the short version, I actually get the script to do a few more things that are not important here):
cnames="nextcloud webserver-name etc."
For i = name in $cnames do
/snap/bin/lxc stop $name
/snap/bin/lxc copy obiwan:$name $name --refresh
/snap/bin/lxc start $name
done
Remarkably, what this simple ‘lxc copy –refresh’ does is to copy the actual live instance of my obiwan server containers to solo and skywalker. Firstly it stops the running container on the backup server (not the live, hot version), then it updates the backup version, then it restarts it. The ‘updating it’ is a key part of the process and lxc ‘copy –refresh’ makes it awesome. You see, when you copy a lxd instance from one machine to another, it can be a bit quirky. A straight ‘lxc copy’ (without the –refresh option) action changes IP and mac address on the new copy, and these can make it difficult to keep track of in the new host system – not good for fail-over. When you use –refresh as an option, it does several important things. FIRSTLY, it only copies over changes that have been made since the last ‘copy –refresh’ – so a 300GB container doesn’t get copied from scratch every time – maybe a few MB or few GB – not much at any time (the first copy takes the longest of course). This is a HUGE benefit, especially when copying over WAN (which I do, but won’t detail here). It’s very fast! Secondly, the IP address and even the MAC address are unchanged in the copy over the original. It is, in every way possible, IDENTICAL copy to the original. That is, to say the least, very handy, when you are trying to create a fail-over service! I totally love ‘copy –refresh’ on lxd.
So a quick copy –refresh every 30 minutes and I have truly hot stand-by servers sitting, waiting for “keepalived” to change their IP so they go live on network vs being in the shadow as a hot backup. Frankly I think this is wonderful. I could go for more frequent copies but for me, 30 minutes is reasonable.
In the event that my primary server (Obiwan) goes down, the haproxy keepalived IP address is switched immediately (<1 second) to Solo and, if necessary finally Skywalker (i.e. I have two failover servers), and each of them is running an “exact copy” of every container I want hot-backed up from Obiwan. In practice, each instance is a maximum 15-30 minutes “old” as that’s how often I copy –refresh. They go live *instantly* when Obiwan goes down and can thus provide me with a very reliable self-hosted service. My containers are completely updated – links, downloads, files, absolutely EVERYTHING down to even the MAC address is identical (max 30 minutes old).
Is this perfect? No.
What I DON’T like about this is that the server can still be up to 30 minutes old – that’s still a window of inconvenience from time to time (e.g. as and when a server goes down and I am not home – it happens). Also, I have to pay attention if a BACKUP server container is actually changed during the primary server downtime – I have to figure out what’s changed so I can sync it to the primary instances on Obiwan when I fix the issues, because right now I only sync one-way (that’s a project for another day). But for me, I manage that risk quite well (I usually know when Obiwan is going down, and I get notifications anyhow, so I can stop ‘making changes’ for a few minutes while Obiwan e.g. reboots). My customers don’t make changes – they just download files, so no issues on back-syncing there.
What I DO like about this is that I can literally lose any two servers and I still have a functioning homelab with customer-visible services. Not bad!
In the earlier days, I have tried playing with lxd clustering, and ceph on my lxd servers to try more slick backup solutions that could be even more in sync in each direction. Nice in theory, but for me, it always gets so complicated that one way or another (probably mostly because of me!), it breaks. THIS SYSTEM I have come up with works because each server is 100% independent. I can pick one up and throw it in the trash and the others have EVERYTHING I need to keep my services going. Not shabby for a homelab.
Technically, I actually do EVEN MORE than this – I also create completely separate copies of my containers that are archived on a daily and weekly basis, but I will save that for another article (hint: zfs deduplication is my hero for that service!).
I love lxd, and I am comfortable running separate servers vs clustering, ceph and other “cool tec” that’s just too hard for me. I can handle “copy –refresh” easily enough.
I hope you find this interesting. 🙂
One question: how do you roll your backups? Let me know on twitter (@OGSelfHosting) or on mastadon (@[email protected]).
Andrew